Algoritmen för k-närmaste grannar (KNN) är en enkel, enkel att implementera övervakad maskininlärningsalgoritm som kan användas för att lösa båda klassificeringarna och regression problem. Paus! Låt oss packa upp det.

En övervakad maskininlärningsalgoritm (i motsats till en oövervakad maskininlärningsalgoritm) är en som förlitar sig på märkt ingångsdata till lära sig en funktion som ger en lämplig utgång när nya omärkta data ges.
Föreställ dig att en dator är ett barn, vi är dess handledare (t.ex. förälder, vårdnadshavare eller lärare) och vi vill ha barnet (datorn) för att lära sig hur en gris ser ut. Vi kommer att visa barnet flera olika bilder, varav några är grisar och resten kan vara bilder på vad som helst (katter, hundar osv.).
När vi ser en gris ropar vi ”gris!” När det inte är en gris ropar vi ”nej, inte gris!” Efter att ha gjort detta flera gånger med barnet visar vi dem en bild och frågar ”gris?” och de kommer korrekt (för det mesta) att säga ”gris!” eller ”nej, inte gris!” beroende på vad bilden är. Det övervakas maskininlärning.

Övervakade algoritmer för maskininlärning används för att lösa klassificerings- eller regressionsproblem.
Ett klassificeringsproblem har ett diskret värde som utdata. Till exempel är ”gillar ananas på pizza” och ”gillar inte ananas på pizza” är diskreta. Det finns ingen mellanväg. Analogin ovan för att lära ett barn att identifiera en gris är ett annat exempel på ett klassificeringsproblem.

Denna bild visar ett grundläggande exempel på hur klassificeringsdata kan se ut. Vi har en prediktor (eller uppsättning prediktorer) och en etikett. På bilden kan vi försöka förutsäga om någon gillar ananas (1) på sin pizza eller inte (0) baserat på deras ålder (prediktorn).
Det är vanlig praxis att representera produktionen ( etikett) för en klassificeringsalgoritm som ett heltal såsom 1, -1 eller 0. I detta fall är dessa tal rent representativa. Matematiska operationer bör inte utföras på dem eftersom det skulle vara meningslöst att göra det. Tänk ett ögonblick. Vad är ”gillar ananas” + ”gillar inte ananas”? Exakt. Vi kan inte lägga till dem, så vi bör inte lägga till deras numeriska representationer.
Ett regressionsproblem har ett reellt tal (ett tal med en decimal) som utdata. Vi kan till exempel använda uppgifterna i tabellen nedan för att uppskatta någons vikt med tanke på deras längd.
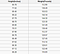
Data som används i en regressionsanalys kommer att likna de data som visas i bilden ovan. Vi har en oberoende variabel (eller uppsättning oberoende variabler) och en beroende variabel (det vi försöker gissa med tanke på våra oberoende variabler). Vi kan till exempel säga att höjd är den oberoende variabeln och vikten är den beroende variabeln.
Dessutom kallas varje rad vanligtvis ett exempel, en observation eller en datapunkt, medan varje kolumn (exklusive etiketten / beroende variabel) kallas ofta en prediktor, dimension, oberoende variabel eller funktion.
En oövervakad maskininlärningsalgoritm använder sig av inmatningsdata utan några etiketter – det vill säga ingen lärare (etikett) säger till barnet (dator) när det är rätt eller när det har gjort ett misstag så att det kan korrigera sig själv.
Till skillnad från övervakat lärande som försöker lära sig en funktion som gör att vi kan göra förutsägelser med tanke på några nya omärkta data , övervakat lärande försöker lära sig den grundläggande strukturen för data för att ge oss mer inblick i data.
K-närmaste grannar
KNN-algoritmen antar att liknande saker finns i närheten . Med andra ord är liknande saker nära varandra.
”En fjäderfågel flockar ihop.”

Observera i bilden ovan att för det mesta är liknande datapunkter nära varandra. KNN-algoritmen bygger på att detta antagande är sant nog för att algoritmen ska vara användbar. KNN fångar tanken på likhet (ibland kallad avstånd, närhet eller närhet) med någon matematik som vi kanske har lärt oss i vår barndom – beräknar avståndet mellan punkter i en graf.
Obs: En förståelse för hur vi beräkna avståndet mellan punkter i ett diagram är nödvändigt innan du går vidare. Om du inte känner till eller behöver en uppdatering av hur denna beräkning görs, läs ”Avstånd mellan 2 poäng” i sin helhet och kom tillbaka igen.
Det finns andra sätt att beräkna avstånd, och en sätt kan vara att föredra beroende på det problem vi löser. Det raka avståndet (även kallat euklidiskt avstånd) är dock ett populärt och välbekant val.
KNN-algoritmen
- Ladda data
- Initiera K till ditt valda antal grannar
3. För varje exempel i data
3.1 Beräkna avståndet mellan frågeexemplet och det aktuella exemplet från data.
3.2 Lägg till avståndet och indexet för exemplet till en ordnad samling
4. Sortera den ordnade samlingen av avstånd och index från minsta till största (i stigande ordning) efter avstånden
5. Välj de första K-posterna från den sorterade samlingen
6. Få etiketterna för de valda K-posterna
7. Om regression, ret urn medelvärdet av K-etiketterna
8. Om klassificering, returnera läget för K-etiketter
KNN-implementeringen (från grunden)
Välja rätt värde för K
För att välja K som passar dina data kör vi KNN-algoritmen flera gånger med olika värden på K och välj K som minskar antalet fel vi stöter på samtidigt som algoritmens förmåga att exakt göra förutsägelser när den får data som den inte har sett tidigare.
Här är några saker att hålla i sinne:
- När vi sänker värdet på K till 1 blir våra förutsägelser mindre stabila. Tänk bara en stund, föreställ dig K = 1 så har vi en frågeställning omgiven av flera röda och en grön (jag tänker på det övre vänstra hörnet på den färgade tomten ovan), men den gröna är den närmaste grannen. Rimligt skulle vi tro att frågan är sannolikt röd, men eftersom K = 1 förutspår KNN felaktigt att frågan är grön.
- Omvänt, när vi ökar värdet på K blir våra förutsägelser mer stabil på grund av majoritetsröstning / genomsnitt, och därmed mer sannolikt att göra mer exakta förutsägelser (upp till en viss punkt). Så småningom börjar vi bevittna ett ökande antal fel. Det är vid denna tidpunkt vi vet att vi har skjutit värdet för K för långt.
- I de fall vi tar majoritetsröstning (t.ex. väljer vi läget i ett klassificeringsproblem) bland etiketter gör vi vanligtvis K ett udda nummer för att ha en tiebreaker.
Fördelar
- Algoritmen är enkel och lätt att implementera.
- Det finns inget behov av bygg en modell, ställ in flera parametrar eller gör ytterligare antaganden.
- Algoritmen är mångsidig. Den kan användas för klassificering, regression och sökning (som vi kommer att se i nästa avsnitt).
Nackdelar
- Algoritmen blir betydligt långsammare när antalet exempel och / eller prediktorer / oberoende variabler ökar.
KNN i praktiken
KNNs största nackdel med att bli betydligt långsammare när datamängden ökar gör det till en opraktiskt val i miljöer där förutsägelser behöver göras snabbt. Dessutom finns det snabbare algoritmer som kan ge mer exakta klassificerings- och regressionsresultat.
Men förutsatt att du har tillräckligt med datorresurser för att snabbt hantera de data du använder för att göra förutsägelser, kan KNN fortfarande vara användbart för att lösa problem som har lösningar som är beroende av att identifiera liknande objekt. Ett exempel på detta är att använda KNN-algoritmen i rekommendatorsystem, en tillämpning av KNN-sökning.
Recommender Systems
I stor skala ser det ut som att rekommendera produkter på Amazon, artiklar om Medium, filmer på Netflix eller videor på YouTube. Vi kan dock vara säkra på att de alla använder effektivare sätt att göra rekommendationer på grund av den enorma datamängden de bearbetar.
Vi kan dock replikera ett av dessa rekommendatorsystem i mindre skala med det vi har lärt sig här i den här artikeln. Låt oss bygga kärnan i ett filmrekommendationssystem.
Vilken fråga försöker vi svara på?
Vilka är de fem filmerna som liknar en filmfråga med tanke på vår filmmängd?
Samla in filmdata
Om vi arbetade på Netflix, Hulu eller IMDb kunde vi hämta informationen från deras datalager. Eftersom vi inte arbetar på något av dessa företag måste vi få vår information på andra sätt. Vi kan använda vissa filmedata från UCI Machine Learning Repository, IMDbs datauppsättning eller noggrant skapa våra egna.
Utforska, rengör och förbered data
Varhelst vi fick våra data , det kan vara några saker fel med det som vi behöver korrigera för att förbereda det för KNN-algoritmen. Data kan till exempel inte vara i det format som algoritmen förväntar sig, eller så kan det saknas värden som vi borde fylla eller ta bort från data innan vi skickar dem till algoritmen.
Vår KNN-implementering ovan bygger på på strukturerade data. Det måste vara i tabellformat. Dessutom antar implementeringen att alla kolumner innehåller numeriska data och att den sista kolumnen i våra data har etiketter som vi kan utföra någon funktion på. Oavsett var vi hämtar våra data måste vi göra att de överensstämmer med dessa begränsningar.
Uppgifterna nedan är ett exempel på vad våra rensade data kan likna. Uppgifterna innehåller trettio filmer, inklusive data för varje film i sju genrer och deras IMDB-betyg. Etikettkolumnen har alla nollor eftersom vi inte använder den här datauppsättningen för klassificering eller regression.
Dessutom finns det förhållanden mellan filmerna som inte kommer att redovisas (t.ex. skådespelare, regissörer och teman) när du använder KNN-algoritmen helt enkelt för att data som fångar dessa förhållanden saknas i datamängden. Följaktligen, när vi kör KNN-algoritmen på våra data, kommer likheten endast att baseras på de inkluderade genrerna och IMDB-klassificeringarna för filmerna.
Använd algoritmen
Föreställ dig en stund . Vi navigerar på MoviesXb-webbplatsen, en fiktiv IMDb-spin-off, och vi stöter på The Post. Vi är inte säkra på att vi vill titta på det, men dess genrer fascinerar oss; vi är nyfikna på andra liknande filmer. Vi rullar ner till avsnittet ”More Like This” för att se vilka rekommendationer MoviesXb kommer att göra, och de algoritmiska växlarna börjar vända.
MoviesXb-webbplatsen skickar en begäran till sin baksida för de fem filmerna som är mest lik The Post. Back-end har en rekommendationsdatauppsättning precis som vår. Det börjar med att skapa radrepresentationen (bättre känd som en funktionsvektor) för The Post, sedan körs ett program som liknar det nedan för att sök efter de 5 filmer som mest liknar The Post och skickar slutligen resultaten tillbaka till MoviesXb-webbplatsen.
När vi kör programmet ser vi att MoviesXb rekommenderar 12 Years A Slave, Hacksaw Ridge, Queen of Katwe, The Wind Rises och A Beautiful Mind Nu när vi förstår hur KNN-algoritmen fungerar kan vi exakt förklara hur KNN-algoritmen kom till dessa rekommendationer. Grattis!
Sammanfattning
K-near est grannar (KNN) algoritm är en enkel, övervakad maskininlärningsalgoritm som kan användas för att lösa både klassificerings- och regressionsproblem. Det är lätt att implementera och förstå, men har en stor nackdel med att bli betydligt långsammare när storleken på den data som används växer.
KNN fungerar genom att hitta avstånden mellan en fråga och alla exemplen i data, att välja de angivna antal exemplen (K) närmast frågan och sedan rösta på den vanligaste etiketten (i fallet med klassificering) eller i genomsnitt göra etiketterna (i fallet med regression).
I fallet med klassificering och regression såg vi att välja rätt K för våra data görs genom att prova flera Ks och välja den som fungerar bäst.
Slutligen tittade vi på ett exempel på hur KNN-algoritmen kunde användas i rekommendatorsystem, en tillämpning av KNN-sökning.