Algoritmul K-nearest neighbors (KNN) este un algoritm de învățare automată supravegheat simplu, ușor de implementat, care poate fi utilizat pentru a rezolva ambele clasificări și probleme de regresie. Pauză! Să despachetăm asta.

Un algoritm de învățare automată supravegheat (spre deosebire de un algoritm de supraveghere automată nesupravegheat) este unul care se bazează pe date de intrare etichetate pentru învățați o funcție care produce o ieșire adecvată atunci când vi se oferă date noi fără etichetă.
Imaginați-vă că un computer este un copil, noi suntem supraveghetorul acestuia (de exemplu, părinte, tutore sau profesor) și vrem copilul (computer) pentru a afla cum arată un porc. Îi vom arăta copilului mai multe imagini diferite, dintre care unele sunt porci, iar restul ar putea fi poze cu orice (pisici, câini etc.).
Când vedem un porc, strigăm „porc!” Când nu este un porc, strigăm „nu, nu porc!” După ce am făcut asta de mai multe ori cu copilul, le arătăm o poză și întrebăm „porc?” și vor spune corect (de cele mai multe ori) „porc!” sau „nu, nu porc!” în funcție de imaginea respectivă. Aceasta este învățarea automată supravegheată.

Algoritmii de învățare automată supravegheați sunt folosiți pentru rezolvarea problemelor de clasificare sau regresie.
O problemă de clasificare are ca ieșire o valoare discretă. De exemplu, „îi place ananasul la pizza” și „nu-i place ananasul la pizza” sunt discrete. Nu există cale de mijloc. Analogia de mai sus a învățării unui copil să identifice un porc este un alt exemplu de problemă de clasificare.

Această imagine prezintă un exemplu de bază despre cum ar putea arăta datele de clasificare. Avem un predictor (sau un set de predictori) și o etichetă. În imagine, s-ar putea să încercăm să prezicem dacă cineva îi place ananasul (1) pe pizza sau nu (0) pe baza vârstei sale (predictorul).
Este o practică standard să se reprezinte rezultatul ( etichetă) a unui algoritm de clasificare ca număr întreg, cum ar fi 1, -1 sau 0. În acest caz, aceste numere sunt pur reprezentative. Operațiile matematice nu ar trebui să fie efectuate asupra lor, deoarece ar fi lipsit de sens. Gândește-te o clipă. Ce este „îi place ananasul” + „nu îi place ananasul”? Exact. Nu le putem adăuga, deci nu ar trebui să le adăugăm reprezentările numerice.
O problemă de regresie are ca rezultat un număr real (un număr cu punct zecimal). De exemplu, am putea folosi datele din tabelul de mai jos pentru a estima greutatea cuiva în funcție de înălțimea lor.
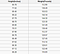
Datele utilizate într-o analiză de regresie vor arăta similar cu datele prezentate în imaginea de mai sus. Avem o variabilă independentă (sau un set de variabile independente) și o variabilă dependentă (lucru pe care încercăm să-l ghicim având în vedere variabilele noastre independente). De exemplu, am putea spune că înălțimea este variabila independentă, iar greutatea este variabila dependentă.
De asemenea, fiecare rând este denumit de obicei un exemplu, o observație sau un punct de date, în timp ce fiecare coloană (fără a include eticheta / variabilă dependentă) este deseori numită predictor, dimensiune, variabilă independentă sau caracteristică.
Un algoritm de supraveghere automată nesupravegheat utilizează datele de intrare fără etichete – cu alte cuvinte, niciun profesor (etichetă) nu îi spune copilului (computer) când este corect sau când a făcut o greșeală, astfel încât să se poată autocorecta.
Spre deosebire de învățarea supravegheată, care încearcă să învețe o funcție care ne va permite să facem predicții, având în vedere unele date noi fără etichetă. , învățarea nesupravegheată încearcă să învețe structura de bază a datelor pentru a ne oferi mai multe informații asupra datelor.
K-Near Neighbours
Algoritmul KNN presupune că lucruri similare există în imediata apropiere . Cu alte cuvinte, lucruri similare sunt apropiate unele de altele.
„Păsările unei pene se adună împreună.”

Observați în imaginea de mai sus că, de cele mai multe ori, puncte de date similare sunt apropiate unele de altele. Algoritmul KNN se bazează pe această ipoteză fiind suficient de adevărată pentru ca algoritmul să fie util. KNN surprinde ideea de asemănare (uneori numită distanță, proximitate sau apropiere) cu unele matematici pe care le-am fi învățat în copilărie – calculând distanța dintre puncte pe un grafic.
Notă: o înțelegere a modului în care calcularea distanței dintre punctele unui grafic este necesară înainte de a trece mai departe. Dacă nu sunteți familiarizați cu sau aveți nevoie de o reîmprospătare a modului în care se face acest calcul, citiți cu atenție „Distanța dintre 2 puncte” în întregime și reveniți imediat.
Există alte modalități de calculare a distanței și una calea ar putea fi preferabilă în funcție de problema pe care o rezolvăm. Cu toate acestea, distanța în linie dreaptă (numită și distanța euclidiană) este o alegere populară și familiară.
Algoritmul KNN
- Încărcați datele
- Inițializați K la numărul ales de vecini
3. Pentru fiecare exemplu din date
3.1 Calculați distanța dintre exemplul de interogare și exemplul curent din date.
3.2 Adăugați distanța și indexul exemplului la o colecție ordonată
4. Sortați colecția ordonată de distanțe și indicii de la cel mai mic la cel mai mare (în ordine crescătoare) după distanțe
5. Alegeți primele K intrări din colecția sortată
6. Obțineți etichetele K intrări selectate
7. Dacă regresia, ret urnați media etichetelor K
8. Dacă clasificați, returnați modul etichetelor K
Implementarea KNN (de la zero)
Alegerea valorii corecte pentru K
Pentru a selecta K-ul potrivit pentru datele dvs., executăm algoritmul KNN de mai multe ori cu diferite valori ale lui K și alegeți K-ul care reduce numărul de erori pe care le întâmpinăm, menținând în același timp capacitatea algoritmului de a face predicții cu exactitate atunci când i se oferă date pe care nu le-a văzut până acum.
Iată câteva lucruri de păstrat minte:
- Pe măsură ce scădem valoarea lui K la 1, predicțiile noastre devin mai puțin stabile. Gândiți-vă un minut, imaginați-vă K = 1 și avem un punct de interogare înconjurat de mai multe roșii și unul verde (mă gândesc la colțul din stânga sus al parcelei colorate de mai sus), dar verdele este cel mai apropiat vecin. În mod rezonabil, am crede că punctul de interogare este cel mai probabil roșu, dar pentru că K = 1, KNN prezice incorect că punctul de interogare este verde.
- Invers, pe măsură ce creștem valoarea lui K, predicțiile noastre devin mai mari stabilă datorită votului majoritar / mediere și, prin urmare, este mai probabil să facă predicții mai exacte (până la un anumit punct). În cele din urmă, începem să asistăm la un număr tot mai mare de erori. În acest moment știm că am împins valoarea K prea mult.
- În cazurile în care luăm un vot majoritar (de exemplu alegerea modului într-o problemă de clasificare) printre etichete, obținem de obicei K un număr impar pentru a avea un tiebreaker.
Avantaje
- Algoritmul este simplu și ușor de implementat.
- Nu este nevoie să construiți un model, reglați mai mulți parametri sau faceți presupuneri suplimentare.
- Algoritmul este versatil. Poate fi folosit pentru clasificare, regresie și căutare (așa cum vom vedea în secțiunea următoare).
Dezavantaje
- Algoritmul devine semnificativ mai lent cu cât numărul de exemple și / sau predictori / variabile independente crește.
KNN în practică
Principalul dezavantaj al KNN de a deveni semnificativ mai lent pe măsură ce volumul de date crește îl face un alegere impracticabilă în medii în care predicțiile trebuie făcute rapid. Mai mult, există algoritmi mai rapizi care pot produce rezultate de clasificare și regresie mai precise.
Cu toate acestea, cu condiția să aveți resurse de calcul suficiente pentru a gestiona rapid datele pe care le utilizați pentru a face predicții, KNN poate fi totuși util în rezolvarea probleme care au soluții care depind de identificarea obiectelor similare. Un exemplu în acest sens este utilizarea algoritmului KNN în sistemele de recomandare, o aplicație de căutare KNN.
Sisteme de recomandare
La scară, ar arăta ca recomandarea produselor pe Amazon, articole pe Medium, filme pe Netflix sau videoclipuri pe YouTube. Deși, putem fi siguri că toți folosesc mijloace mai eficiente de a face recomandări datorită volumului enorm de date pe care le procesează.
Cu toate acestea, am putea reproduce unul dintre aceste sisteme de recomandare pe o scară mai mică folosind ceea ce avem învățat aici în acest articol. Să construim nucleul unui sistem de recomandare a filmelor.
La ce întrebare încercăm să răspundem?
Având în vedere setul nostru de date despre filme, care sunt cele mai similare 5 filme cu o interogare de film?
Adună date despre filme
Dacă am lucra la Netflix, Hulu sau IMDb, am putea prelua datele din depozitul lor de date. Deoarece nu lucrăm la niciuna dintre aceste companii, trebuie să ne obținem datele prin alte mijloace. Am putea folosi unele date despre filme din UCI Machine Learning Repository, setul de date IMDb sau să le creăm cu grijă pe ale noastre.
Explorează, curăță și pregătește datele
Oriunde am obținut datele noastre , pot exista unele lucruri în neregulă pe care trebuie să le corectăm pentru a-l pregăti pentru algoritmul KNN. De exemplu, este posibil ca datele să nu fie în formatul pe care îl așteaptă algoritmul sau pot lipsi valori pe care ar trebui să le completăm sau să le eliminăm din date înainte de a le introduce în algoritm.
Implementarea noastră KNN de mai sus se bazează pe date structurate. Trebuie să fie în format tabel. În plus, implementarea presupune că toate coloanele conțin date numerice și că ultima coloană a datelor noastre are etichete pe care putem îndeplini anumite funcții. Deci, de oriunde am obținut datele noastre, trebuie să le facem conforme cu aceste constrângeri.
Datele de mai jos sunt un exemplu de cum ar putea asemăna datele noastre curățate. Datele conțin treizeci de filme, inclusiv date pentru fiecare film din șapte genuri și evaluările lor IMDB. Coloana de etichete are toate zerourile, deoarece nu folosim acest set de date pentru clasificare sau regresie.
În plus, există relații între filme care nu vor fi luate în considerare (de exemplu, actori, regizori și teme) atunci când se utilizează algoritmul KNN pur și simplu deoarece datele care captează acele relații lipsesc din setul de date. În consecință, atunci când rulăm algoritmul KNN pe datele noastre, similitudinea se va baza exclusiv pe genurile incluse și pe evaluările IMDB ale filmelor.
Utilizați algoritmul
Imaginați-vă pentru o clipă . Navigăm pe site-ul MoviesXb, un spin-off IMDb fictiv și ne întâlnim cu The Post. Nu suntem siguri că vrem să-l urmărim, dar genurile sale ne intrigă; suntem curioși de alte filme similare. Derulăm în jos până la secțiunea „Mai mult ca acesta” pentru a vedea ce recomandări vor face MoviesXb și uneltele algoritmice încep să se întoarcă.
Site-ul MoviesXb trimite o cerere către back-end-ul său pentru cele 5 filme care sunt cele mai asemănătoare cu The Post. Back-end-ul are un set de date de recomandare exact ca al nostru. Începe prin crearea reprezentării rândurilor (mai bine cunoscut ca vector de caracteristici) pentru The Post, apoi rulează un program similar cu cel de mai jos pentru căutați cele 5 filme care sunt cele mai asemănătoare cu The Post și, în cele din urmă, trimite rezultatele înapoi pe site-ul MoviesXb.
Când rulăm acest program, vedem că MoviesXb recomandă 12 Years A Slave, Hacksaw Ridge, Queen of Katwe, The Wind Rises și A Beautiful Mind Acum că înțelegem pe deplin cum funcționează algoritmul KNN, putem explica exact modul în care algoritmul KNN a făcut aceste recomandări. Felicitări!
Rezumat
K-near Algoritmul este vecinii (KNN) este un algoritm de învățare automată simplu, supravegheat, care poate fi utilizat atât pentru rezolvarea problemelor de clasificare, cât și de regresie. Este ușor de implementat și de înțeles, dar are un dezavantaj major de a deveni semnificativ mai lent, pe măsură ce dimensiunea acelor date utilizate crește.
KNN funcționează găsind distanțele dintre o interogare și toate exemplele din date, selectând exemplele de număr specificate (K) cele mai apropiate de interogare, apoi votează pentru cea mai frecventă etichetă (în cazul clasificării) sau calculează media etichetelor (în cazul regresiei).
În cazul clasificare și regresie, am văzut că alegerea K-ului potrivit pentru datele noastre se face încercând mai multe K-uri și alegând-o pe cea care funcționează cel mai bine.
În cele din urmă, am analizat un exemplu al modului în care algoritmul KNN ar putea fi utilizat în sistemele de recomandare, o aplicație de căutare KNN.