O algoritmo k-vizinhos mais próximos (KNN) é um algoritmo de aprendizado de máquina supervisionado simples e fácil de implementar que pode ser usado para resolver ambas as classificações e problemas de regressão. Pausa! Vamos desempacotar isso.

Um algoritmo de aprendizado de máquina supervisionado (em oposição a um algoritmo de aprendizado de máquina não supervisionado) é aquele que depende de dados de entrada rotulados para aprender uma função que produza uma saída apropriada quando recebe novos dados não rotulados.
Imagine que um computador é uma criança, nós somos seus supervisores (por exemplo, pai, tutor ou professor), e queremos a criança (computador) para aprender a aparência de um porco. Vamos mostrar à criança várias imagens diferentes, algumas das quais são porcos e as restantes podem ser imagens de qualquer coisa (gatos, cães, etc.).
Quando vemos um porco, gritamos “porco!” Quando não é um porco, gritamos “não, porco não!” Depois de fazer isso várias vezes com a criança, mostramos uma foto e perguntamos “porco?” e eles dirão corretamente (na maioria das vezes) “porco!” ou “não, porco não!” dependendo da imagem. Isso é aprendizado de máquina supervisionado.

Algoritmos de aprendizado de máquina supervisionados são usados para resolver problemas de classificação ou regressão.
Um problema de classificação tem um valor discreto como sua saída. Por exemplo, “gosta de abacaxi na pizza” e “não gosta de abacaxi na pizza” são discretos. Não há meio termo. A analogia acima de ensinar uma criança a identificar um porco é outro exemplo de um problema de classificação.

Esta imagem mostra um exemplo básico de como os dados de classificação podem ser. Temos um preditor (ou conjunto de preditores) e um rótulo. Na imagem, podemos tentar prever se alguém gosta de abacaxi (1) em sua pizza ou não (0) com base em sua idade (o preditor).
É uma prática padrão representar o resultado ( rótulo) de um algoritmo de classificação como um número inteiro, como 1, -1 ou 0. Nesse caso, esses números são puramente representacionais. Operações matemáticas não devem ser executadas neles porque isso não teria sentido. Pense um pouco. O que é “gosta de abacaxi” + “não gosta de abacaxi”? Exatamente. Não podemos adicioná-los, então não devemos adicionar suas representações numéricas.
Um problema de regressão tem um número real (um número com um ponto decimal) como sua saída. Por exemplo, poderíamos usar os dados da tabela abaixo para estimar o peso de alguém de acordo com sua altura.
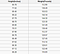
Os dados usados em uma análise de regressão serão semelhantes aos dados mostrados na imagem acima. Temos uma variável independente (ou conjunto de variáveis independentes) e uma variável dependente (o que estamos tentando adivinhar dadas as nossas variáveis independentes). Por exemplo, poderíamos dizer que a altura é a variável independente e o peso é a variável dependente.
Além disso, cada linha é normalmente chamada de exemplo, observação ou ponto de dados, enquanto cada coluna (sem incluir o rótulo / variável dependente) costuma ser chamada de preditor, dimensão, variável independente ou recurso.
Um algoritmo de aprendizado de máquina não supervisionado usa dados de entrada sem rótulos – em outras palavras, nenhum professor (rótulo) informa à criança (computador) quando está certo ou quando cometeu um erro para que possa se autocorrigir.
Ao contrário da aprendizagem supervisionada, que tenta aprender uma função que nos permitirá fazer previsões, dados alguns novos dados não rotulados , o aprendizado não supervisionado tenta aprender a estrutura básica dos dados para nos dar mais insights sobre os dados.
K-vizinhos mais próximos
O algoritmo KNN assume que coisas semelhantes existem nas proximidades . Em outras palavras, coisas semelhantes estão próximas umas das outras.
“Pássaros da mesma pena voam juntos.”

Observe na imagem acima que na maioria das vezes, pontos de dados semelhantes estão próximos uns dos outros. O algoritmo KNN depende dessa suposição ser verdadeira o suficiente para que o algoritmo seja útil. KNN captura a ideia de semelhança (às vezes chamada de distância, proximidade ou proximidade) com alguma matemática que podemos ter aprendido em nossa infância – calculando a distância entre pontos em um gráfico.
Nota: Uma compreensão de como nós calcular a distância entre os pontos de um gráfico é necessário antes de prosseguir. Se você não está familiarizado ou precisa de uma atualização sobre como esse cálculo é feito, leia cuidadosamente “Distância entre 2 pontos” na íntegra e volte agora.
Existem outras maneiras de calcular a distância, e uma pode ser preferível, dependendo do problema que estamos resolvendo. No entanto, a distância em linha reta (também chamada de distância euclidiana) é uma escolha popular e familiar.
O algoritmo KNN
- Carregue os dados
- Inicialize K para o número escolhido de vizinhos
3. Para cada exemplo nos dados
3.1 Calcule o distância entre o exemplo de consulta e o exemplo atual dos dados.
3.2 Adicione a distância e o índice do exemplo a uma coleção ordenada
4. Classifique a coleção ordenada de distâncias e índices do menor para o maior (em ordem crescente) pelas distâncias
5. Escolha as primeiras K entradas da coleção ordenada
6. Obtenha os rótulos das K entradas selecionadas
7. Se regressão, ret urna a média dos rótulos K
8. Se for classificação, retorne o modo dos rótulos K
A implementação KNN (do zero)
Escolhendo o valor certo para K
Para selecionar o K certo para seus dados, executamos o algoritmo KNN várias vezes com diferentes valores de K e escolha o K que reduz o número de erros que encontramos, enquanto mantém a capacidade do algoritmo de fazer previsões com precisão quando recebe dados que não foram vistos antes.
Aqui estão algumas coisas para manter mente:
- Conforme diminuímos o valor de K para 1, nossas previsões se tornam menos estáveis. Pense por um minuto, imagine K = 1 e temos um ponto de consulta cercado por vários vermelhos e um verde (estou pensando no canto superior esquerdo do gráfico colorido acima), mas o verde é o único vizinho mais próximo. Razoavelmente, poderíamos pensar que o ponto de consulta provavelmente é vermelho, mas como K = 1, KNN prevê incorretamente que o ponto de consulta é verde.
- Inversamente, conforme aumentamos o valor de K, nossas previsões se tornam mais estável devido à votação por maioria / média e, portanto, mais provável de fazer previsões mais precisas (até certo ponto). Eventualmente, começamos a testemunhar um número crescente de erros. É neste ponto que sabemos que levamos o valor de K longe demais.
- Nos casos em que estamos realizando uma votação majoritária (por exemplo, escolhendo o modo em um problema de classificação) entre os rótulos, normalmente fazemos K um número ímpar para ter um desempate.
Vantagens
- O algoritmo é simples e fácil de implementar.
- Não há necessidade de construir um modelo, ajustar vários parâmetros ou fazer suposições adicionais.
- O algoritmo é versátil. Ele pode ser usado para classificação, regressão e pesquisa (como veremos na próxima seção).
Desvantagens
- O algoritmo fica significativamente mais lento conforme o número de exemplos e / ou preditores / variáveis independentes aumenta.
KNN na prática
A principal desvantagem do KNN de se tornar significativamente mais lento à medida que o volume de dados aumenta o torna um escolha impraticável em ambientes onde as previsões precisam ser feitas rapidamente. Além disso, existem algoritmos mais rápidos que podem produzir resultados de classificação e regressão mais precisos.
No entanto, desde que você tenha recursos de computação suficientes para lidar rapidamente com os dados que está usando para fazer previsões, o KNN ainda pode ser útil na solução problemas que têm soluções que dependem da identificação de objetos semelhantes. Um exemplo disso é o uso do algoritmo KNN em sistemas de recomendação, uma aplicação de pesquisa KNN.
Sistemas de recomendação
Em escala, isso pareceria recomendar produtos na Amazon, artigos sobre Meio, filmes no Netflix ou vídeos no YouTube. No entanto, podemos ter certeza de que todos usam meios mais eficientes de fazer recomendações devido ao enorme volume de dados que processam.
No entanto, poderíamos replicar um desses sistemas de recomendação em uma escala menor usando o que temos aprendi aqui neste artigo. Vamos construir o núcleo de um sistema de recomendação de filmes.
Que pergunta estamos tentando responder?
Dado nosso conjunto de dados de filmes, quais são os 5 filmes mais semelhantes a uma consulta de filme?
Reúna dados de filmes
Se trabalhássemos no Netflix, Hulu ou IMDb, poderíamos obter os dados de seu data warehouse. Como não trabalhamos em nenhuma dessas empresas, temos que obter nossos dados por outros meios. Poderíamos usar alguns dados de filmes do UCI Machine Learning Repository, conjunto de dados da IMDb ou criar nosso próprio meticulosamente.
Explorar, limpar e preparar os dados
Onde quer que obtivemos nossos dados , pode haver algumas coisas erradas com ele que precisamos corrigir para prepará-lo para o algoritmo KNN. Por exemplo, os dados podem não estar no formato que o algoritmo espera, ou pode haver valores ausentes que devemos preencher ou remover dos dados antes de canalizá-los para o algoritmo.
Nossa implementação KNN acima depende em dados estruturados. Ele precisa estar em formato de tabela. Além disso, a implementação assume que todas as colunas contêm dados numéricos e que a última coluna de nossos dados tem rótulos nos quais podemos executar alguma função. Portanto, de onde quer que tenhamos nossos dados, precisamos torná-los em conformidade com essas restrições.
Os dados abaixo são um exemplo de como nossos dados limpos podem se parecer. Os dados contêm trinta filmes, incluindo dados para cada filme em sete gêneros e suas classificações IMDB. A coluna de rótulos só contém zeros porque não estamos usando esse conjunto de dados para classificação ou regressão.
Além disso, existem relações entre os filmes que não serão contabilizadas (por exemplo, atores, diretores e temas) ao usar o algoritmo KNN simplesmente porque os dados que capturam essas relações estão ausentes do conjunto de dados. Conseqüentemente, quando executamos o algoritmo KNN em nossos dados, a similaridade será baseada apenas nos gêneros incluídos e nas classificações IMDB dos filmes.
Use o algoritmo
Imagine por um momento . Estamos navegando no site MoviesXb, um spin-off fictício da IMDb, e encontramos o The Post. Não temos certeza se queremos assistir, mas seus gêneros nos intrigam; estamos curiosos sobre outros filmes semelhantes. Rolaremos para baixo até a seção “Mais como este” para ver quais recomendações o MoviesXb fará, e as engrenagens algorítmicas começam a girar.
O site MoviesXb envia uma solicitação ao back-end para os 5 filmes que são mais semelhantes ao The Post. O back-end tem um conjunto de dados de recomendação exatamente como o nosso. Ele começa criando a representação da linha (mais conhecido como vetor de recursos) para o The Post e, em seguida, executa um programa semelhante ao seguinte para pesquise os 5 filmes mais semelhantes ao The Post e, finalmente, envie os resultados de volta ao site MoviesXb.
Quando executamos este programa, vemos que MoviesXb recomenda 12 Years A Slave, Hacksaw Ridge, Queen of Katwe, The Wind Rises e A Beautiful Mind . Agora que entendemos perfeitamente como o algoritmo KNN funciona, podemos explicar exatamente como o algoritmo KNN veio a fazer essas recomendações. Parabéns!
Resumo
O k-near O algoritmo est neighbours (KNN) é um algoritmo simples de aprendizado de máquina supervisionado que pode ser usado para resolver problemas de classificação e regressão. É fácil de implementar e entender, mas tem uma grande desvantagem de se tornar significativamente mais lento à medida que o tamanho dos dados em uso aumenta.
O KNN funciona encontrando as distâncias entre uma consulta e todos os exemplos nos dados, selecionar os exemplos de números especificados (K) mais próximos da consulta e, em seguida, votar no rótulo mais frequente (no caso de classificação) ou fazer a média dos rótulos (no caso de regressão).
No caso de classificação e regressão, vimos que escolher o K certo para nossos dados é feito tentando vários Ks e escolhendo aquele que funciona melhor.
Por fim, vimos um exemplo de como o algoritmo KNN poderia ser usado em sistemas de recomendação, uma aplicação de pesquisa KNN.