Algorytm k-najbliższych sąsiadów (KNN) to prosty, łatwy do wdrożenia algorytm nadzorowanego uczenia maszynowego, który można wykorzystać do rozwiązania obu klasyfikacji i problemy z regresją. Pauza! Rozpakujmy to.

Nadzorowany algorytm uczenia maszynowego (w przeciwieństwie do nienadzorowanego algorytmu uczenia maszynowego) to taki, który opiera się na oznaczonych danych wejściowych nauczyć się funkcji, która generuje odpowiednie dane wyjściowe po otrzymaniu nowych, nieoznaczonych danych.
Wyobraź sobie, że komputer jest dzieckiem, jesteśmy jego opiekunem (np. rodzicem, opiekunem lub nauczycielem) i chcemy, aby dziecko (komputer) aby dowiedzieć się, jak wygląda świnia. Pokażemy dziecku kilka różnych zdjęć, z których niektóre przedstawiają świnie, a reszta może być zdjęciami czegokolwiek (kotów, psów itp.).
Kiedy widzimy świnię, krzyczymy „świnia!” Kiedy to nie jest świnia, krzyczymy „nie, nie świnia!” Po kilkukrotnym zrobieniu tego z dzieckiem pokazujemy mu zdjęcie i pytamy „świnia?” i będą poprawnie (przez większość czasu) mówić „świnia!” lub „nie, nie świnia!” w zależności od obrazu. To jest nadzorowane uczenie maszynowe.

Nadzorowane algorytmy uczenia maszynowego są używane do rozwiązywania problemów związanych z klasyfikacją lub regresją.
Problem klasyfikacji ma dyskretną wartość na wyjściu. Na przykład „lubi ananasa na pizzy” i „nie lubi ananasa na pizzy” są dyskretne. Nie ma żadnego środka. Powyższa analogia do uczenia dziecka rozpoznawania świni to kolejny przykład problemu klasyfikacyjnego.

Ten obraz przedstawia podstawowy przykład tego, jak mogą wyglądać dane klasyfikacyjne. Mamy predyktor (lub zestaw predyktorów) i etykietę. Na obrazku możemy próbować przewidzieć, czy ktoś lubi ananasa (1) w swojej pizzy, czy nie (0) na podstawie jego wieku (predyktor).
Standardową praktyką jest przedstawianie wyniku ( label) algorytmu klasyfikacji jako liczba całkowita, taka jak 1, -1 lub 0. W tym przypadku liczby te mają wyłącznie charakter reprezentacyjny. Nie należy wykonywać na nich operacji matematycznych, ponieważ byłoby to bez znaczenia. Pomyśl przez chwilę. Co to jest „lubi ananas” + „nie lubi ananasa”? Dokładnie. Nie możemy ich dodać, więc nie powinniśmy dodawać ich liczbowych reprezentacji.
Problem regresji ma na wyjściu liczbę rzeczywistą (liczbę z przecinkiem). Na przykład moglibyśmy wykorzystać dane z poniższej tabeli do oszacowania wagi osoby na podstawie jej wzrostu.
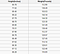
Dane użyte w analizie regresji będą wyglądać podobnie do danych pokazanych na powyższym obrazku. Mamy zmienną niezależną (lub zbiór zmiennych niezależnych) i zmienną zależną (rzecz, którą próbujemy odgadnąć, biorąc pod uwagę nasze zmienne niezależne). Na przykład możemy powiedzieć, że wysokość jest zmienną niezależną, a waga zmienną zależną.
Ponadto każdy wiersz jest zwykle nazywany przykładem, obserwacją lub punktem danych, podczas gdy każda kolumna (bez etykiety / zmienna zależna) jest często nazywana predyktorem, wymiarem, zmienną niezależną lub cechą.
Nienadzorowany algorytm uczenia maszynowego wykorzystuje dane wejściowe bez żadnych etykiet – innymi słowy, żaden nauczyciel (etykieta) nie mówi dziecku (komputer), gdy ma rację lub gdy popełnił błąd, aby mógł się samokorygować.
W przeciwieństwie do nadzorowanego uczenia się, które próbuje nauczyć się funkcji, która pozwoli nam przewidywać na podstawie nowych nieoznaczonych danych , uczenie się bez nadzoru próbuje nauczyć się podstawowej struktury danych, aby dać nam lepszy wgląd w dane.
K-najbliżsi sąsiedzi
Algorytm KNN zakłada, że podobne rzeczy istnieją w bliskiej odległości . Innymi słowy, podobne rzeczy są blisko siebie.
„Ptaki z piór gromadzą się razem.”

Zauważ, że na powyższym obrazku przez większość czasu podobne punkty danych znajdują się blisko siebie. Algorytm KNN opiera się na założeniu, które jest wystarczająco prawdziwe, aby algorytm był użyteczny. KNN oddaje ideę podobieństwa (czasami nazywaną odległością, bliskością lub bliskością) z pewną matematyką, której mogliśmy się nauczyć w dzieciństwie – obliczając odległość między punktami na wykresie.
Uwaga: zrozumienie tego, jak my obliczenie odległości między punktami na wykresie jest konieczne przed przejściem dalej. Jeśli nie znasz lub potrzebujesz przypomnienia sobie, jak wykonuje się te obliczenia, przeczytaj dokładnie „Odległość między 2 punktami” i od razu wróć.
Istnieją inne sposoby obliczania odległości, a jeden metoda może być lepsza w zależności od problemu, który rozwiązujemy. Jednak odległość w linii prostej (zwana również odległością euklidesową) jest popularnym i znanym wyborem.
Algorytm KNN
- Załaduj dane
- Zainicjuj K do wybranej liczby sąsiadów
3. Dla każdego przykładu w danych
3.1 Oblicz odległość między przykładem zapytania a bieżącym przykładem z danych.
3.2 Dodaj odległość i indeks przykładu do uporządkowanej kolekcji
4. Sortuj uporządkowany zbiór odległości i indeksy od najmniejszego do największego (w porządku rosnącym) według odległości
5. Wybierz pierwsze K pozycji z posortowanej kolekcji
6. Pobierz etykiety wybranych K wpisów
7. Jeśli regresja, ret urn średnią etykiet K
8. Jeśli klasyfikacja, zwróć tryb K etykiet
Implementacja KNN (od zera)
Wybór właściwej wartości K
Aby wybrać K odpowiednie dla danych, kilkakrotnie uruchamiamy algorytm KNN z różne wartości K i wybierz K, które zmniejsza liczbę błędów, które napotykamy, przy jednoczesnym zachowaniu zdolności algorytmu do dokładnego przewidywania, gdy podane są dane, których wcześniej nie widział.
Oto kilka rzeczy, na które należy zwrócić uwagę umysł:
- Gdy zmniejszamy wartość K do 1, nasze przewidywania stają się mniej stabilne. Pomyśl przez chwilę, wyobraź sobie K = 1 i mamy punkt zapytania otoczony kilkoma czerwonymi i jednym zielonym (myślę o lewym górnym rogu kolorowego wykresu powyżej), ale zielony jest najbliższym sąsiadem. Rozsądnie myślelibyśmy, że punkt zapytania jest najprawdopodobniej czerwony, ale ponieważ K = 1, KNN nieprawidłowo przewiduje, że punkt zapytania jest zielony.
- Odwrotnie, gdy zwiększamy wartość K, nasze przewidywania stają się bardziej stabilny ze względu na głosowanie większościowe / uśrednianie, a tym samym bardziej prawdopodobne, że będą dokładniej przewidywać (do pewnego momentu). W końcu zaczynamy być świadkami coraz większej liczby błędów. W tym momencie wiemy, że przesunęliśmy wartość K. zbyt daleko.
- W przypadkach, w których bierzemy większość głosów (np. Wybierając tryb w problemie klasyfikacji) wśród etykiet, zwykle ustawiamy K nieparzysta liczba, aby rozstrzygnąć remis.
Zalety
- Algorytm jest prosty i łatwy do wdrożenia.
- Nie ma potrzeby zbudować model, dostroić kilka parametrów lub przyjąć dodatkowe założenia.
- Algorytm jest wszechstronny. Może być używany do klasyfikacji, regresji i wyszukiwania (jak zobaczymy w następnej sekcji).
Wady
- Algorytm staje się znacznie wolniejszy, gdy liczba przykładów i / lub predyktorów / zmiennych niezależnych rośnie.
KNN w praktyce
Główna wada KNN polegająca na tym, że staje się znacznie wolniejsza wraz ze wzrostem ilości danych, sprawia, że wybór niepraktyczny w środowiskach, w których trzeba szybko przewidywać. Ponadto istnieją szybsze algorytmy, które mogą dawać dokładniejsze wyniki klasyfikacji i regresji.
Jednak pod warunkiem, że masz wystarczające zasoby obliczeniowe, aby szybko obsłużyć dane używane do prognozowania, KNN może być nadal przydatny w rozwiązywaniu problemy, których rozwiązania zależą od identyfikacji podobnych obiektów. Przykładem tego jest użycie algorytmu KNN w systemach rekomendujących, aplikacja KNN-search.
Systemy rekomendujące
W dużej skali wyglądałoby to tak, jak rekomendowanie produktów na Amazon, artykuły na Medium, filmy w serwisie Netflix lub filmy na YouTube. Chociaż możemy być pewni, że wszyscy używają bardziej skutecznych sposobów przedstawiania zaleceń ze względu na ogromną ilość danych, które przetwarzają.
Możemy jednak powielić jeden z tych systemów rekomendujących na mniejszą skalę, korzystając z tego, co mamy dowiedziałem się tutaj w tym artykule. Zbudujmy rdzeń systemu rekomendacji filmów.
Na jakie pytanie staramy się odpowiedzieć?
Biorąc pod uwagę nasz zestaw danych dotyczących filmów, jakie jest 5 filmów najbardziej podobnych do zapytania o film?
Zbierz dane dotyczące filmów
Gdybyśmy pracowali w Netflix, Hulu lub IMDb, moglibyśmy pobrać dane z ich hurtowni danych. Ponieważ nie pracujemy w żadnej z tych firm, musimy pozyskiwać nasze dane w inny sposób. Moglibyśmy użyć danych z filmów z repozytorium UCI Machine Learning Repository, zbioru danych IMDb lub żmudnego stworzenia własnego.
Eksplorować, czyścić i przygotowywać dane
Gdziekolwiek uzyskaliśmy nasze dane , może być z nim nie tak, że musimy go poprawić, aby przygotować go do algorytmu KNN. Na przykład dane mogą nie mieć formatu oczekiwanego przez algorytm lub mogą brakować wartości, które powinniśmy wypełnić lub usunąć z danych przed przesłaniem ich do algorytmu.
Nasza powyższa implementacja KNN opiera się na na danych strukturalnych. Musi być w formacie tabeli. Dodatkowo implementacja zakłada, że wszystkie kolumny zawierają dane liczbowe, a ostatnia kolumna naszych danych ma etykiety, na których możemy wykonać jakąś funkcję. Tak więc, gdziekolwiek otrzymaliśmy nasze dane, musimy dostosować je do tych ograniczeń.
Poniższe dane są przykładem tego, jak mogą wyglądać nasze oczyszczone dane. Dane obejmują trzydzieści filmów, w tym dane dla każdego filmu z siedmiu gatunków i ich oceny IMDB. Kolumna etykiety zawiera wszystkie zera, ponieważ nie używamy tego zbioru danych do klasyfikacji ani regresji.
Ponadto istnieją relacje między filmami, które nie będą uwzględniane (np. aktorzy, reżyserzy i motywy) podczas korzystania z algorytmu KNN po prostu dlatego, że w zestawie danych brakuje danych, które rejestrują te relacje. W konsekwencji, kiedy uruchomimy algorytm KNN na naszych danych, podobieństwo będzie oparte wyłącznie na uwzględnionych gatunkach i ocenach filmów w IMDB.
Użyj algorytmu
Wyobraź sobie przez chwilę . Poruszamy się po stronie MoviesXb, fikcyjnej spin-offie IMDb, i napotykamy The Post. Nie jesteśmy pewni, czy chcemy go obejrzeć, ale jego gatunki nas intrygują; jesteśmy ciekawi innych podobnych filmów. Przewijamy w dół do sekcji „Więcej podobnych”, aby zobaczyć, jakie rekomendacje przedstawi MoviesXb, a algorytmiczne koła zębate zaczną się obracać.
Witryna MoviesXb wysyła do zaplecza żądanie 5 filmów, które są najbardziej podobne do The Post. Back-end ma zestaw danych rekomendacji dokładnie taki jak nasz. Rozpoczyna się od utworzenia reprezentacji wiersza (lepiej znanej jako wektor cech) dla The Post, a następnie uruchamia program podobny do poniższego wyszukaj 5 filmów, które są najbardziej podobne do The Post, a na koniec odeślij wyniki z powrotem do witryny MoviesXb.
Kiedy uruchamiamy ten program, widzimy, że MoviesXb poleca 12 lat niewolnika, Hacksaw Ridge, Queen of Katwe, The Wind Rises i A Beautiful Mind . Teraz, gdy w pełni rozumiemy, jak działa algorytm KNN, jesteśmy w stanie dokładnie wyjaśnić, w jaki sposób algorytm KNN doszedł do tych zaleceń. Gratulacje!
Podsumowanie
K-near Algorytm est sąsiadów (KNN) jest prostym, nadzorowanym algorytmem uczenia maszynowego, który może być używany do rozwiązywania problemów klasyfikacji i regresji. Jest łatwy do zaimplementowania i zrozumienia, ale ma poważną wadę polegającą na tym, że znacznie spowalnia wraz ze wzrostem rozmiaru używanych danych.
KNN działa poprzez znajdowanie odległości między zapytaniem a wszystkimi przykładami w danych, wybierając określoną liczbę przykładów (K) najbliżej zapytania, następnie głosuje na najczęściej występującą etykietę (w przypadku klasyfikacji) lub uśrednia etykiety (w przypadku regresji).
W przypadku klasyfikacji i regresji, widzieliśmy, że wybranie właściwego K dla naszych danych odbywa się poprzez wypróbowanie kilku K i wybranie tego, które działa najlepiej.
Na koniec przyjrzeliśmy się przykładowi, jak można wykorzystać algorytm KNN w systemach rekomendujących zastosowanie wyszukiwania KNN.