Dit is de tweede in een reeks artikelen over subquerys. In dit artikel bespreken we subquerys in de kolomlijst van de SELECT-instructie. Andere artikelen bespreken hun gebruik in andere clausules.
Alle voorbeelden voor deze les zijn gebaseerd op Microsoft SQL Server Management Studio en de AdventureWorks2012-database. U kunt aan de slag met het gebruik van deze gratis tools met behulp van mijn Gids Aan de slag met SQL Server.
Subquerys gebruiken in de Select-instructie
Wanneer een subquery in de kolomlijst wordt geplaatst, wordt deze gebruikt om retourneer enkele waarden. In dit geval kunt u de subquery zien als een expressie met één waarde. Het geretourneerde resultaat is niet anders dan de uitdrukking “2 + 2”. Natuurlijk kunnen subquerys ook tekst retourneren, maar u begrijpt het wel!
Wanneer u met subquerys werkt, wordt de hoofdinstructie soms de buitenste query genoemd. Subquerys staan tussen haakjes, dit maakt ze gemakkelijker te herkennen .
Wees voorzichtig bij het gebruik van subquerys. Ze kunnen leuk zijn om te gebruiken, maar naarmate u meer aan uw query toevoegt, kunnen ze uw query vertragen.
Eenvoudige subquery om het gemiddelde te berekenen
Laten we beginnen met een eenvoudige vraag om SalesOrderDetail te tonen en die te vergelijken met het algemene gemiddelde SalesOrderDetail LineTotal. De SELECT-instructie die we zullen gebruiken is:
SELECT SalesOrderID,LineTotal,(SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail) AS AverageLineTotalFROM Sales.SalesOrderDetail;
Deze query retourneert resultaten als:
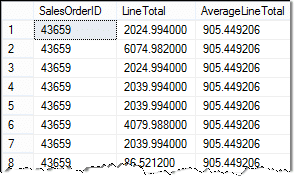
De subquery, die hierboven in rood wordt weergegeven, wordt als eerste uitgevoerd om het gemiddelde LineTotal te verkrijgen.
SELECT AVG(LineTotal)FROM Sales.SalesOrderDetail
Dit resultaat wordt vervolgens teruggeplaatst in de kolomlijst en de query gaat verder. Er zijn verschillende dingen die ik wil aangeven :
- Subquerys staan tussen haakjes .
- Wanneer subquerys worden gebruikt in een SELECT-instructie, kunnen ze slechts één waarde retourneren. Dit zou logisch moeten zijn, het simpelweg selecteren van een kolom retourneert één waarde voor een rij, en we moeten hetzelfde patroon volgen.
- In het algemeen wordt de subquery slechts één keer uitgevoerd voor de hele query, en het resultaat wordt opnieuw gebruikt . Dit komt doordat het zoekresultaat niet voor elke geretourneerde rij verschilt.
- Het is belangrijk om aliassen voor de kolomnamen te gebruiken om de leesbaarheid te verbeteren.
Simpele subquery in expressie
Zoals je mag verwachten, kan het resultaat van een subquery in andere uitdrukkingen worden gebruikt. Laten we, voortbouwend op het vorige voorbeeld, de subquery gebruiken om te bepalen hoeveel ons LineTotal afwijkt van het gemiddelde.
De variantie is simpelweg het LineTotal minus het Average Line-totaal. In de volgende subquery heb ik het blauw gekleurd. Hier is de formule voor de variantie:
LineTotal - (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail)
De SELECT-instructie tussen haakjes is de subquery. Net als het eerdere voorbeeld zal deze query één keer worden uitgevoerd en een numerieke waarde retourneren, die vervolgens wordt afgetrokken van elke LineTotal-waarde.
Hier is de query in definitieve vorm:
SELECT SalesOrderID, LineTotal, (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail) AS AverageLineTotal, LineTotal - (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail) AS VarianceFROM Sales.SalesOrderDetail
Hier is het resultaat:
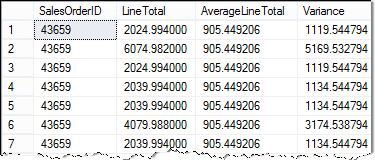
Wanneer ik met subquerys in geselecteerde statements werk, bouw ik meestal en test eerst de subquery. SELECT-instructies kunnen erg snel ingewikkeld worden. Het is het beste om ze beetje bij beetje op te bouwen. Door de verschillende onderdelen afzonderlijk te bouwen en te testen, helpt het echt bij het opsporen van fouten.
Gecorreleerde zoekopdrachten
Er zijn manieren om de waarden van de buitenste zoekopdracht op te nemen in de clausules van de subquery. Dit soort querys worden gecorreleerde subquerys genoemd, aangezien de resultaten van de subquery in een of andere vorm zijn verbonden met waarden in de buitenste query. Gecorreleerde zoekopdrachten worden soms gesynchroniseerde zoekopdrachten genoemd.
Als u niet weet wat correleren betekent, bekijk dan deze definitie van Google:
Correleren: “een wederzijdse relatie of verbinding hebben, waarin het ene een ander beïnvloedt of ervan afhangt. ”
Een typisch gebruik voor een gecorreleerde subquery wordt gebruikt in een van de kolommen van de buitenste query in de WHERE-clausule van de binnenquery. Dit is in veel gevallen gezond verstand beperk de innerlijke query tot een subset van gegevens.
Voorbeeld van gecorreleerde subquery
We geven een voorbeeld van een gecorreleerde subquery door elk SalesOrderDetail LineTotal terug te rapporteren, en het gemiddelde LineTotal voor de totale Sales Order.
Dit verzoek verschilt aanzienlijk van onze eerdere voorbeelden, aangezien het gemiddelde dat we berekenen voor elke verkooporder verschilt.
Dit is waar gecorreleerde subquerys een rol spelen. We kunnen een waarde uit de buitenste query en neem deze op in de filtercriteria van de subquery.
Laten we een kijk hoe we het gemiddelde lijntotaal berekenen. Om dit te doen heb ik een illustratie samengesteld die de SELECT-instructie met subquery laat zien.
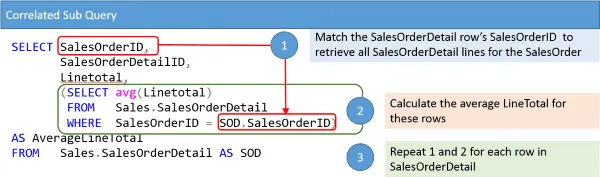
Om verder uit te werken op de diagram. De SELECT-instructie bestaat uit twee delen: de buitenste query en de subquery. De buitenste query wordt gebruikt om alle SalesOrderDetail-regels op te halen.De subquery wordt gebruikt om regels voor verkoopordergegevens voor een specifieke SalesOrderID te zoeken en samen te vatten.
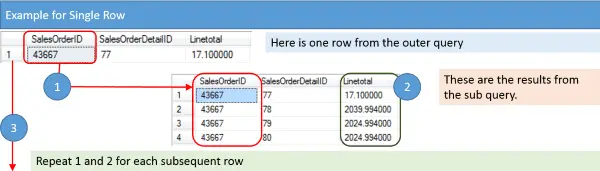
Als ik de stappen zou moeten verwoorden we gaan nemen, zou ik ze als volgt samenvatten:
- Haal de SalesOrderID op.
- Retourneer het gemiddelde lijntotaal van alle SalesOrderDetail-items waar de SalesOrderID overeenkomt.
- Ga verder naar de volgende SalesOrderID in de buitenste query en herhaal stap 1 en 2.
De query die u kunt uitvoeren in de AdventureWork2012-database is:
SELECT SalesOrderID, SalesOrderDetailID, LineTotal, (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail WHERE SalesOrderID = SOD.SalesOrderID) AS AverageLineTotalFROM Sales.SalesOrderDetail SOD
Dit zijn de resultaten van de zoekopdracht:
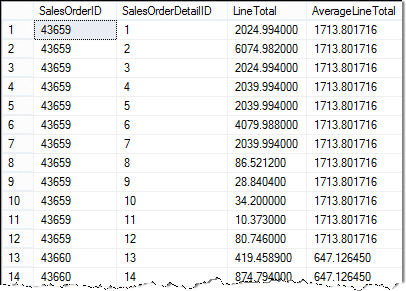
Er zijn een paar items om erop te wijzen.
- Je kunt zien dat ik kolomaliassen heb gebruikt om de zoekresultaten beter leesbaar te maken.
- Ik heb ook een tabelalias, SOD, gebruikt voor de uiterlijke vraag. Dit maakt het mogelijk om de waarden van de buitenste query in de subquery te gebruiken. Anders is de zoekopdracht niet gecorreleerd!
- Door de tabelaliassen te gebruiken, wordt het ondubbelzinnig gemaakt welke kolommen uit elke tabel komen.
De gecorreleerde subquery opsplitsen
Laten we dit nu proberen op te splitsen met behulp van SQL.
Laten we om te beginnen aannemen dat we alleen ons voorbeeld voor SalesOrderDetailID 20 krijgen. De bijbehorende SalesOrderID is 43661.
Het is eenvoudig om het gemiddelde LineTotal voor dit item te krijgen.
SELECT AVG(LineTotal)FROM Sales.SalesOrderDetailWHERE SalesOrderID = 43661
Dit geeft de waarde 2181.765240 terug.
Nu we het gemiddelde hebben, kunnen we plug het in onze zoekopdracht
SELECT SalesOrderID, SalesOrderDetailID, LineTotal, 2181.765240 AS AverageLineTotalFROM Sales.SalesOrderDetailWHERE SalesOrderDetailID = 20
Met behulp van subquerys wordt dit
SELECT SalesOrderID, SalesOrderDetailID, LineTotal, (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail WHERE SalesOrderID = 43661) AS AverageLineTotalFROM Sales.SalesOrderDetailWHERE SalesOrderDetailID = 20
Laatste vraag is :
SELECT SalesOrderID, SalesOrderDetailID, LineTotal, (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetailWHERE SalesOrderID = SOD.SalesOrderID) AS AverageLineTotalFROM Sales.SalesOrderDetail AS SOD
Gecorreleerde subquery met een andere tabel
Een gecorreleerde subquery, of wat dat betreft elke subquery, kan een andere tabel gebruiken dan de uiterlijke vraag. Dit kan handig zijn wanneer u met een “bovenliggende” tabel werkt, zoals SalesOrderHeader, en u een samenvatting van onderliggende rijen wilt opnemen in het resultaat, zoals die van SalesOrderDetail.
Laten we de OrderDate, TotalDue en aantal detailregels voor verkooporders. Hiervoor kunnen we het volgende diagram gebruiken om ons te oriënteren:
Om dit te doen, nemen we een gecorreleerde subquery op in onze SELECT-instructie om het COUNT SalesOrderDetail-regels te retourneren. We zorgen ervoor dat we het juiste SalesOrderDetail-item tellen door te filteren op de SalesOrderID van de buitenste query.
Hier is de laatste SELECT-instructie:
SELECT SalesOrderID, OrderDate, TotalDue, (SELECT COUNT(SalesOrderDetailID) FROM Sales.SalesOrderDetail WHERE SalesOrderID = SO.SalesOrderID) as LineCountFROM Sales.SalesOrderHeader SO
De resultaten zijn:
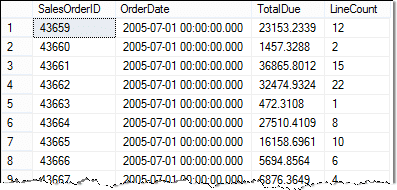
Enkele dingen die opvallen bij dit voorbeeld zijn:
- De subquery selecteert gegevens uit een andere tabel dan de buitenste query.
- Ik heb tabel en kolomaliassen om het gemakkelijker te maken om de SQL en resultaten te lezen.
- Zorg ervoor dat u dubbel controleert k je waar clausule! Als u vergeet de tabelnaam of aliassen op te nemen in de WHERE-component van de subquery, wordt de query niet gecorreleerd.
Gecorreleerde subquerys versus innerlijke joins
Het is belangrijk om te begrijpen dat u dezelfde resultaten kunt krijgen met een subquery of een join. Hoewel beide dezelfde resultaten opleveren, heeft elke methode voor- en nadelen!
Beschouw het laatste voorbeeld waarin we regelitems tellen voor SalesHeader-items.
SELECT SalesOrderID, OrderDate, TotalDue, (SELECT COUNT(SalesOrderDetailID) FROM Sales.SalesOrderDetailWHERE SalesOrderID = SO.SalesOrderID) as LineCountFROM Sales.SalesOrderHeader SO
Dezelfde zoekopdracht kan worden gedaan met een INNER JOIN samen met GROUP BY als
SELECT SO.SalesOrderID, OrderDate, TotalDue, COUNT(SOD.SalesOrderDetailID) as LineCountFROM Sales.SalesOrderHeader SO INNER JOIN Sales.SalesOrderDetail SOD ON SOD.SalesOrderID = SO.SalesOrderIDGROUP BY SO.SalesOrderID, OrderDate, TotalDue
Welke is sneller?
Je zult merken dat veel mensen zullen zeggen dat ze subquerys moeten vermijden omdat ze langzamer zijn. Ze zullen beweren dat de gecorreleerde subquery eenmaal moet worden “uitgevoerd” voor elke rij die in de buitenste query wordt geretourneerd, terwijl de INNER JOIN slechts één keer door de gegevens hoeft te gaan.
Ikzelf? Ik zeg uitchecken het queryplan. Ik volgde mijn eigen advies voor beide bovenstaande voorbeelden en vond dat de plannen hetzelfde waren!
Dat wil niet zeggen dat de plannen zouden veranderen als er meer gegevens waren, maar mijn punt is dat je niet alleen maar aannames moet doen. De meeste SQL DBMS-optimizers zijn erg goed in het uitzoeken van de beste manier om je query uit te voeren. Ze nemen je syntaxis, zoals een subquery of INNER JOIN, en gebruiken deze om een feitelijk uitvoeringsplan.
Welke is gemakkelijker te lezen?
Afhankelijk van waar u zich prettig bij voelt, vindt u het INNER JOIN-voorbeeld misschien gemakkelijker te lezen dan de gecorreleerde zoekopdracht. Persoonlijk, in dit voorbeeld vind ik de gecorreleerde subquery leuk omdat deze directer lijkt. Het is gemakkelijker voor mij om te zien wat er wordt geteld.
Naar mijn mening is de INNER JOIN minder direct. Eerst moet u zien dat alle rijen met verkoopdetails met de hand worden geretourneerd en vervolgens worden samengevat. Je begrijpt dit pas echt als je de hele verklaring hebt gelezen.
Welke is beter?
Laat me weten wat je ervan vindt. Ik zou graag willen horen of je liever de gecorreleerde subquery of het INNER JOIN-voorbeeld gebruikt.