Het k-dichtstbijzijnde-buren-algoritme (KNN) is een eenvoudig, gemakkelijk te implementeren algoritme voor machinaal leren onder supervisie dat kan worden gebruikt om beide classificaties op te lossen. en regressieproblemen. Pauze! Laten we dat uitpakken.

Een algoritme voor machine learning onder supervisie (in tegenstelling tot een algoritme voor machine learning zonder toezicht) is een algoritme dat afhankelijk is van gelabelde invoergegevens om leer een functie die een geschikte output produceert wanneer nieuwe ongelabelde gegevens worden gegeven.
Stel je voor dat een computer een kind is, wij zijn supervisor (bijv. ouder, voogd of leraar), en we willen het kind (computer) om te leren hoe een varken eruitziet. We zullen het kind verschillende afbeeldingen laten zien, waarvan sommige varkens zijn en de rest afbeeldingen van alles (katten, honden, enz.).
Als we een varken zien, roepen we “varken!” Als het geen varken is, roepen we “nee, geen varken!” Nadat we dit verschillende keren met het kind hebben gedaan, laten we ze een foto zien en vragen we “varken?” en ze zullen correct (meestal) zeggen “varken!” of “nee, geen varken!” afhankelijk van de afbeelding. Dat is machinaal leren onder toezicht.

Supervised machine learning-algoritmen worden gebruikt om classificatie- of regressieproblemen op te lossen.
Een classificatieprobleem heeft een discrete waarde als output. Bijvoorbeeld, “houdt van ananas op pizza” en “houdt niet van ananas op pizza” zijn discreet. Er is geen middenweg. De bovenstaande analogie van het leren van een kind om een varken te identificeren, is een ander voorbeeld van een classificatieprobleem.

Deze afbeelding toont een eenvoudig voorbeeld van hoe classificatiegegevens eruit zouden kunnen zien. We hebben een voorspeller (of set voorspellers) en een label. In de afbeelding proberen we mogelijk te voorspellen of iemand ananas (1) op zijn pizza lekker vindt of niet (0) op basis van zijn leeftijd (de voorspeller).
Het is een standaardpraktijk om de output weer te geven ( label) van een classificatie-algoritme als een geheel getal, zoals 1, -1 of 0. In dit geval zijn deze getallen puur representatief. Er mogen geen wiskundige bewerkingen op worden uitgevoerd, omdat dit zinloos zou zijn. Denk even na. Wat is “houdt van ananas” + “houdt niet van ananas”? Precies. We kunnen ze niet toevoegen, dus we moeten hun numerieke representaties niet toevoegen.
Een regressieprobleem heeft een reëel getal (een getal met een decimaalteken) als uitvoer. We kunnen bijvoorbeeld de gegevens in de onderstaande tabel gebruiken om iemands gewicht te schatten op basis van hun lengte.
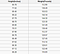
De gegevens die in een regressieanalyse worden gebruikt, zien er hetzelfde uit als de gegevens die in de bovenstaande afbeelding worden getoond. We hebben een onafhankelijke variabele (of een reeks onafhankelijke variabelen) en een afhankelijke variabele (het ding dat we proberen te raden gezien onze onafhankelijke variabelen). We zouden bijvoorbeeld kunnen zeggen dat hoogte de onafhankelijke variabele is en het gewicht de afhankelijke variabele.
Bovendien wordt elke rij typisch een voorbeeld, observatie of gegevenspunt genoemd, terwijl elke kolom (exclusief het label / afhankelijke variabele) wordt vaak een voorspeller, dimensie, onafhankelijke variabele of functie genoemd.
Een niet-gecontroleerd algoritme voor machine learning maakt gebruik van invoergegevens zonder labels, met andere woorden, geen leraar (label) die het kind vertelt (computer) wanneer het goed is of wanneer het een fout heeft gemaakt, zodat het zichzelf kan corrigeren.
In tegenstelling tot begeleid leren dat probeert een functie te leren waarmee we voorspellingen kunnen doen op basis van enkele nieuwe niet-gelabelde gegevens probeert onbewaakt leren de basisstructuur van de gegevens te leren om ons meer inzicht in de gegevens te geven.
K-Dichtstbijzijnde buren
Het KNN-algoritme gaat ervan uit dat soortgelijke dingen in de directe omgeving bestaan . Met andere woorden, soortgelijke dingen zijn dicht bij elkaar.
“Vogels van een veer komen samen.”

Merk in de afbeelding hierboven op dat vergelijkbare gegevenspunten meestal dicht bij elkaar liggen. Het KNN-algoritme hangt ervan af dat deze aanname waar genoeg is om het algoritme bruikbaar te maken. KNN legt het idee vast van gelijkenis (soms afstand, nabijheid of nabijheid genoemd) met wat wiskunde die we misschien in onze kindertijd hebben geleerd – de afstand tussen punten op een grafiek berekenen.
Opmerking: een begrip van hoe we bereken de afstand tussen punten in een grafiek voordat u verder gaat. Als je niet bekend bent met of een opfriscursus nodig hebt over hoe deze berekening wordt uitgevoerd, lees dan “Afstand tussen 2 punten” in zijn geheel grondig door en kom meteen terug.
Er zijn andere manieren om de afstand te berekenen, en een manier kan de voorkeur hebben, afhankelijk van het probleem dat we oplossen. De afstand in een rechte lijn (ook wel de Euclidische afstand genoemd) is een populaire en bekende keuze.
Het KNN-algoritme
- Laad de gegevens
- Initialiseer K naar het door u gekozen aantal buren
3. Voor elk voorbeeld in de gegevens
3.1 Bereken de afstand tussen het queryvoorbeeld en het huidige voorbeeld uit de gegevens.
3.2 Voeg de afstand en de index van het voorbeeld toe aan een geordende verzameling
4. Sorteer de geordende verzameling afstanden en indices van klein naar groot (in oplopende volgorde) door de afstanden
5. Kies de eerste K-items uit de gesorteerde verzameling
6. Verkrijg de labels van de geselecteerde K-items
7. Als regressie, ret urn het gemiddelde van de K-labels
8. Als classificatie, retourneer de modus van de K-labels
De KNN-implementatie (vanaf nul)
De juiste waarde kiezen voor K
Om de K te selecteren die geschikt is voor uw gegevens, voeren we het KNN-algoritme verschillende keren uit met verschillende waarden van K en kies de K die het aantal fouten vermindert dat we tegenkomen, terwijl het algoritme in staat blijft om nauwkeurig voorspellingen te doen wanneer het gegevens krijgt die het nog niet eerder heeft gezien.
Hier zijn enkele dingen om in te houden geest:
- Als we de waarde van K verlagen naar 1, worden onze voorspellingen minder stabiel. Denk eens even na, stel je voor dat K = 1 en we hebben een vraagpunt omringd door verschillende rode en een groene (ik denk aan de linkerbovenhoek van de gekleurde plot hierboven), maar de groene is de enige dichtstbijzijnde buur. We zouden redelijkerwijs denken dat het zoekpunt waarschijnlijk rood is, maar omdat K = 1, KNN ten onrechte voorspelt dat het zoekpunt groen is.
- Omgekeerd, naarmate we de waarde van K verhogen, worden onze voorspellingen meer stabiel vanwege stemming bij meerderheid / gemiddelde, en dus waarschijnlijker om nauwkeurigere voorspellingen te doen (tot een bepaald punt). Uiteindelijk beginnen we getuige te worden van een toenemend aantal fouten. Op dit punt weten we dat we de waarde van K te ver hebben doorgeschoven.
- In gevallen waarin we een meerderheid van stemmen nemen (bijvoorbeeld als we de modus kiezen in een classificatieprobleem) tussen de labels, maken we meestal K een oneven getal om een schiftingsgraad te hebben.
Voordelen
- Het algoritme is eenvoudig en gemakkelijk te implementeren.
- Het is niet nodig om bouw een model, stem verschillende parameters af of doe aanvullende aannames.
- Het algoritme is veelzijdig. Het kan worden gebruikt voor classificatie, regressie en zoeken (zoals we zullen zien in de volgende sectie).
Nadelen
- Het algoritme wordt aanzienlijk langzamer naarmate het aantal voorbeelden en / of voorspellers / onafhankelijke variabelen neemt toe.
KNN in de praktijk
Het belangrijkste nadeel van KNN dat het aanzienlijk langzamer wordt naarmate het datavolume toeneemt, maakt het een onpraktische keuze in omgevingen waar snel voorspellingen moeten worden gedaan. Bovendien zijn er snellere algoritmen die nauwkeurigere classificatie- en regressieresultaten kunnen produceren.
Als u echter over voldoende computerbronnen beschikt om de gegevens die u gebruikt om voorspellingen te doen, snel te verwerken, kan KNN nog steeds nuttig zijn bij het oplossen van problemen die oplossingen hebben die afhankelijk zijn van het identificeren van vergelijkbare objecten. Een voorbeeld hiervan is het gebruik van het KNN-algoritme in aanbevelingssystemen, een toepassing van KNN-zoeken.
Aanbevelingssystemen
Op schaal zou dit lijken op het aanbevelen van producten op Amazon, artikelen over Medium, films op Netflix of videos op YouTube. Hoewel we er zeker van kunnen zijn dat ze allemaal efficiëntere middelen gebruiken om aanbevelingen te doen vanwege de enorme hoeveelheid gegevens die ze verwerken.
We zouden echter een van deze aanbevelingssystemen op kleinere schaal kunnen repliceren met wat we hebben geleerd hier in dit artikel. Laten we de kern van een aanbevelingssysteem voor films bouwen.
Welke vraag proberen we te beantwoorden?
Gezien onze filmgegevensverzameling, wat zijn de 5 films die het meest lijken op een filmquery?
Verzamel filmgegevens
Als we bij Netflix, Hulu of IMDb zouden werken, zouden we de gegevens uit hun datawarehouse kunnen halen. Aangezien we bij geen van deze bedrijven werken, moeten we onze gegevens op een andere manier verkrijgen. We zouden enkele filmgegevens kunnen gebruiken uit de UCI Machine Learning Repository, de dataset van IMDb, of zorgvuldig onze eigen gegevens kunnen maken.
De gegevens onderzoeken, opschonen en voorbereiden
Waar we onze gegevens ook hebben verkregen , kunnen er enkele dingen mis mee zijn die we moeten corrigeren om het voor te bereiden op het KNN-algoritme. De gegevens hebben bijvoorbeeld mogelijk niet de indeling die het algoritme verwacht, of er kunnen waarden ontbreken die we moeten invullen of verwijderen uit de gegevens voordat we deze in het algoritme doorsluizen.
Onze bovenstaande KNN-implementatie is gebaseerd op op gestructureerde gegevens. Het moet in tabelformaat zijn. Bovendien gaat de implementatie ervan uit dat alle kolommen numerieke gegevens bevatten en dat de laatste kolom van onze gegevens labels heeft waarop we een functie kunnen uitvoeren. Dus, waar we onze gegevens ook vandaan halen, we moeten ervoor zorgen dat ze voldoen aan deze beperkingen.
De onderstaande gegevens zijn een voorbeeld van hoe onze opgeschoonde gegevens eruit kunnen zien. De gegevens bevatten dertig films, inclusief gegevens voor elke film in zeven genres en hun IMDB-beoordelingen. De kolom met labels bevat allemaal nullen omdat we deze gegevensset niet gebruiken voor classificatie of regressie.
Bovendien zijn er relaties tussen de films waarmee geen rekening wordt gehouden (bijv. acteurs, regisseurs en themas) bij gebruik van het KNN-algoritme simpelweg omdat de gegevens die deze relaties vastleggen, ontbreken in de gegevensset. Als we het KNN-algoritme op onze gegevens uitvoeren, wordt de overeenkomst dus uitsluitend gebaseerd op de opgenomen genres en de IMDB-beoordelingen van de films.
Gebruik het algoritme
Stel je eens voor . We navigeren door de MoviesXb-website, een fictieve IMDb-spin-off, en we komen The Post tegen. We weten niet zeker of we ernaar willen kijken, maar de genres intrigeren ons; we zijn benieuwd naar andere soortgelijke films. We scrollen omlaag naar het gedeelte Meer zoals dit om te zien welke aanbevelingen MoviesXb zal doen, en de algoritmische versnellingen beginnen te draaien.
De MoviesXb-website stuurt een verzoek naar de back-end voor de 5 films die lijken het meest op The Post. De back-end heeft een aanbevelingsdataset precies zoals die van ons. Het begint met het maken van de rijweergave (beter bekend als een feature-vector) voor The Post, en voert vervolgens een programma uit dat lijkt op het onderstaande programma om zoek naar de 5 films die het meest op The Post lijken en stuur de resultaten ten slotte terug naar de MoviesXb-website.
Als we dit programma uitvoeren, zien we dat MoviesXb 12 Years A Slave, Hacksaw Ridge, Queen of Katwe, The Wind Rises en A Beautiful Mind aanbeveelt . Nu we volledig begrijpen hoe het KNN-algoritme werkt, kunnen we precies uitleggen hoe het KNN-algoritme tot deze aanbevelingen kwam. Gefeliciteerd!
Samenvatting
De k-near est neighbours (KNN) -algoritme is een eenvoudig, gecontroleerd algoritme voor machine learning dat kan worden gebruikt om zowel classificatie- als regressieproblemen op te lossen. Het is gemakkelijk te implementeren en te begrijpen, maar heeft als groot nadeel dat het aanzienlijk trager wordt naarmate de omvang van de gebruikte gegevens toeneemt.
KNN werkt door de afstanden te vinden tussen een zoekopdracht en alle voorbeelden in de gegevens, het selecteren van de gespecificeerde aantal voorbeelden (K) die het dichtst bij de vraag liggen, stemt vervolgens op het meest voorkomende label (in het geval van classificatie) of neemt het gemiddelde van de labels (in het geval van regressie).
In het geval van classificatie en regressie, we zagen dat het kiezen van de juiste K voor onze gegevens wordt gedaan door verschillende Ks te proberen en degene te kiezen die het beste werkt.
Ten slotte hebben we gekeken naar een voorbeeld van hoe het KNN-algoritme zou kunnen worden gebruikt in aanbevelingssystemen, een toepassing van KNN-search.