Vi så at det er mulig å bruke forskjellige formede funksjoner (kurver) for å modellere data. Velge hvilken kurve som skal brukes (lineær, kvadratisk, eksponentiell) var lett så lenge spredningsdiagrammet viste en likhet med den faktiske kurven. Men hva om det er uklart hvilken kurve du skal velge?
(lineær versus ikke-lineær)
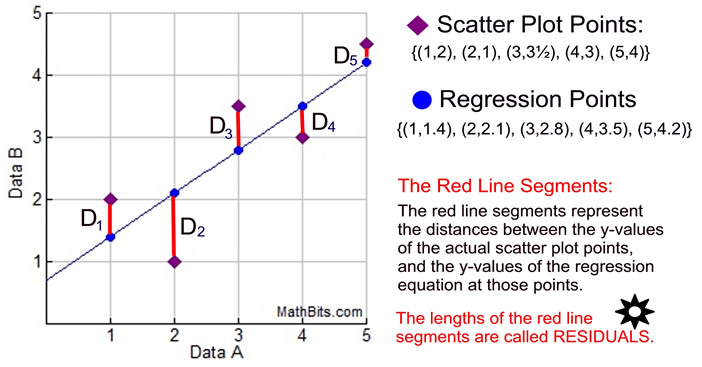
En rest er forskjellen mellom det som er plottet i spredningsplottet ditt på et bestemt punkt, og hva regresjonsligningen forutsier at «skal plottes» på dette spesifikke punktet. Hvis spredningsdiagrammet og regresjonsligningen «er enige» om en y-verdi (ingen forskjell), vil resten være null.
|
||||
Lineære assosiasjoner er de mest populære statistiske forholdene, siden de er enkle å lese og tolke. Vi vil bruke mesteparten av tiden vår på å jobbe med lineære forhold, og rester kan fortelle oss når vi har en passende lineær modell.
Når du ser på spredningsdiagrammet ditt, og du er usikker på om formen (kurven) du valgte for regresjonsligningen din vil skape den beste modellen, et restplott vil hjelpe deg med å ta en beslutning om modellen du valgte vil eller ikke vil være en passende lineær modell.
Passende lineær modell: når plottene er tilfeldig plassert, over og under x-aksen (y = 0).
Passende ikke-lineær modell: når diagrammer følger et mønster, ligner på en kurve.
|
Du blir bedt om å finne en ligning for å modellere dataene i settet {(1,2), (2,1), (3,3½), (4,3), (5,4½)}. Du forbereder en spred plott for å se om du skal lete etter en lineær, kvadratisk eller eksponentiell regresjonsligning. Du bestemmer deg for å velge en lineær regresjon, men du er ikke 100% sikker på ditt valg. Du bruker din grafkalkulator for å finne den lineære regresjonsligningen, som er y = 0,7x + 0,7. Du tegner linjen for regresjonsligningen på spredningsdiagrammet, som vist nedenfor. |
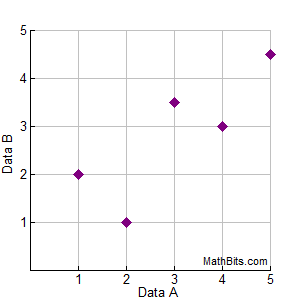 |
|

![]()
Restprodukter var grunnlaget for den statistisk avtalt definisjonen av en «best passende linje (eller kurve) «.
D12 + D22 + … + Dn2 vil være et minimum.
En kurve som har denne egenskapen, der kvadratet av de vertikale avstandene fra datapunktene til kurven er så liten som mulig , kalles en minste kvadratkurve.
Regresjonslinje med minste kvadrater = Regresjonslinje av «Best» Fit
![]()
Rester på grafkalkulatoren:
|
Når regresjonsmodeller er beregnet på grafkalkulatoren, lagres rester automatisk i en liste som heter RESID. Følg lenkene nedenfor for å se hvordan du arbeider med rester på kalkulatoren din.
|
|||||||
|
|
||||||
