KN-nærmeste nabo (ALG) algoritme er en enkel, enkel å implementere overvåket maskinlæringsalgoritme som kan brukes til å løse begge klassifiseringene. og regresjonsproblemer. Pause! La oss pakke ut det.

En overvåket maskinlæringsalgoritme (i motsetning til en ikke-overvåket algoritme for maskinlæring) er en som er avhengig av merket inngangsdata til lære en funksjon som gir en passende utgang når du får nye umerkede data.
Tenk deg at en datamaskin er et barn, vi er veileder for det (f.eks. foreldre, verge eller lærer), og vi vil ha barnet (datamaskinen) for å lære hvordan en gris ser ut. Vi vil vise barnet flere forskjellige bilder, hvorav noen er griser, og resten kan være bilder av hva som helst (katter, hunder osv.).
Når vi ser en gris, roper vi «gris!» Når det ikke er en gris, roper vi «nei, ikke gris!» Etter å ha gjort dette flere ganger med barnet, viser vi dem et bilde og spør «gris?» og de vil riktig (mesteparten av tiden) si «gris!» eller «nei, ikke gris!» avhengig av hva bildet er. Det er tilsyn med maskinlæring.

Overvåket maskinlæringsalgoritmer brukes til å løse klassifiserings- eller regresjonsproblemer.
Et klassifiseringsproblem har en diskret verdi som utdata. For eksempel er «liker ananas på pizza» og «liker ikke ananas på pizza» er diskrete. Det er ingen mellomting. Analogien ovenfor om å lære et barn å identifisere en gris er et annet eksempel på et klassifiseringsproblem.

Dette bildet viser et grunnleggende eksempel på hvordan klassifiseringsdata kan se ut. Vi har en prediktor (eller sett med prediktorer) og en etikett. På bildet prøver vi kanskje å forutsi om noen liker ananas (1) på pizzaen deres eller ikke (0) basert på deres alder (prediktoren).
Det er vanlig praksis å representere utdataene ( etikett) av en klassifiseringsalgoritme som et heltall slik som 1, -1 eller 0. I dette tilfellet er disse tallene rent representative. Matematiske operasjoner bør ikke utføres på dem fordi det ville være meningsløst å gjøre det. Tenk et øyeblikk. Hva er «liker ananas» + «liker ikke ananas»? Nøyaktig. Vi kan ikke legge dem til, så vi bør ikke legge til deres numeriske representasjoner.
Et regresjonsproblem har et reelt tall (et tall med et desimaltegn) som utgang. For eksempel kan vi bruke dataene i tabellen nedenfor til å estimere noen vekt gitt høyden.
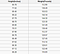
Data som brukes i en regresjonsanalyse, vil ligne på dataene vist i bildet ovenfor. Vi har en uavhengig variabel (eller sett med uavhengige variabler) og en avhengig variabel (tingen vi prøver å gjette gitt våre uavhengige variabler). For eksempel kan vi si at høyden er den uavhengige variabelen, og vekten er den avhengige variabelen.
Dessuten kalles hver rad vanligvis et eksempel, observasjon eller datapunkt, mens hver kolonne (ikke inkludert etiketten / avhengig variabel) kalles ofte en prediktor, dimensjon, uavhengig variabel eller funksjon.
En ikke-overvåket algoritme for maskinlæring bruker inndata uten merkelapper – med andre ord, ingen lærer (etikett) som forteller barnet (datamaskin) når det er riktig eller når det har gjort en feil slik at den kan korrigere seg selv.
I motsetning til veiledet læring som prøver å lære en funksjon som vil tillate oss å komme med spådommer gitt noen nye umerkede data , uten tilsyn læring prøver å lære den grunnleggende strukturen til dataene for å gi oss mer innsikt i dataene.
K-nærmeste naboer
KNN-algoritmen antar at lignende ting eksisterer i nærheten . Med andre ord er lignende ting nær hverandre.
«Fjærfugler strømmer sammen.”

Legg merke til i bildet over at lignende datapunkter oftest er nær hverandre. KNN-algoritmen baserer seg på at denne antagelsen er sant nok til at algoritmen kan være nyttig. KNN fanger ideen om likhet (noen ganger kalt avstand, nærhet eller nærhet) med noe matematikk vi kanskje hadde lært i barndommen – beregner avstanden mellom punktene i en graf.
Merk: En forståelse av hvordan vi beregne avstanden mellom punktene i en graf er nødvendig før du går videre. Hvis du ikke er kjent med eller trenger en forfriskning om hvordan denne beregningen gjøres, må du lese «Avstand mellom 2 poeng» i sin helhet og komme tilbake.
Det er andre måter å beregne avstand på, og en måte kan være å foretrekke avhengig av problemet vi løser. Imidlertid er den rette linjeavstanden (også kalt euklidisk avstand) et populært og kjent valg.
KNN-algoritmen
- Last inn dataene
- Initialiser K til det valgte antallet naboer
3. For hvert eksempel i dataene
3.1 Beregn avstand mellom spørreeksemplet og gjeldende eksempel fra dataene.
3.2 Legg avstanden og indeksen til eksemplet til en ordnet samling
4. Sorter den ordnede samlingen av avstander og indekser fra minste til største (i stigende rekkefølge) etter avstandene
5. Velg de første K-oppføringene fra den sorterte samlingen
6. Få etikettene til de valgte K-oppføringene
7. Hvis regresjon, ret urn gjennomsnittet av K-etikettene
8. Hvis klassifisering, returner modusen til K-etikettene
KNN-implementeringen (fra bunnen av)
Velge riktig verdi for K
For å velge K som er riktig for dine data, kjører vi KNN-algoritmen flere ganger med forskjellige verdier av K og velg K som reduserer antall feil vi støter på mens du opprettholder algoritmens evne til å presisere nøyaktig når det er gitt data den ikke har sett før.
Her er noen ting du må ha i sinn:
- Når vi reduserer verdien av K til 1, blir våre spådommer mindre stabile. Bare tenk et øyeblikk, tenk deg K = 1, og vi har et spørringspunkt omgitt av flere røde og en grønn (jeg tenker på øverste venstre hjørne av det fargede plottet ovenfor), men det grønne er den nærmeste nabo. Rimeligvis vil vi tro at spørringspunktet mest sannsynlig er rødt, men fordi K = 1 forutsier KNN feil at spørringspunktet er grønt.
- Omvendt, når vi øker verdien av K, blir våre spådommer mer stabil på grunn av flertallstemming / gjennomsnitt, og dermed mer sannsynlig å gi mer nøyaktige spådommer (opp til et visst punkt). Til slutt begynner vi å være vitne til et økende antall feil. Det er på dette tidspunktet vi vet at vi har presset verdien av K for langt.
- I tilfeller der vi tar flertall (f.eks. Velger modus i et klassifiseringsproblem) blant etiketter, lager vi vanligvis K et oddetall for å ha en tiebreaker.
Fordeler
- Algoritmen er enkel og enkel å implementere.
- Det er ikke nødvendig å bygg en modell, still inn flere parametere, eller legg til flere antakelser.
- Algoritmen er allsidig. Den kan brukes til klassifisering, regresjon og søk (som vi vil se i neste avsnitt).
Ulemper
- Algoritmen blir betydelig langsommere når antall eksempler og / eller prediktorer / uavhengige variabler øker.
KNN i praksis
KNNs største ulempe med å bli betydelig langsommere etter hvert som datamengden øker gjør det til et upraktisk valg i miljøer der spådommer må gjøres raskt. Videre er det raskere algoritmer som kan gi mer nøyaktige klassifiserings- og regresjonsresultater.
Imidlertid, forutsatt at du har tilstrekkelige databehandlingsressurser til å raskt håndtere dataene du bruker for å forutsi, kan KNN fortsatt være nyttig i å løse problemer som har løsninger som avhenger av å identifisere lignende objekter. Et eksempel på dette er å bruke KNN-algoritmen i anbefalingssystemer, en applikasjon av KNN-søk.
Anbefalingssystemer
I målestokk vil dette se ut som å anbefale produkter på Amazon, artikler om Medium, filmer på Netflix eller videoer på YouTube. Selv om vi kan være sikre på at de alle bruker mer effektive metoder for å komme med anbefalinger på grunn av det enorme datamengden de behandler.
Vi kan imidlertid replikere et av disse anbefalingssystemene i mindre skala ved å bruke det vi har lært her i denne artikkelen. La oss bygge kjernen i et filmanbefalingssystem.
Hvilket spørsmål prøver vi å svare på?
Hva er de 5 mest like filmene til et filmspørsmål, gitt datasettene våre?
Samle inn filmdata
Hvis vi jobbet hos Netflix, Hulu eller IMDb, kunne vi hente dataene fra datalageret deres. Siden vi ikke jobber hos noen av disse selskapene, må vi få dataene våre på andre måter. Vi kan bruke filmedata fra UCI Machine Learning Repository, IMDbs datasett, eller omhyggelig lage våre egne.
Utforsk, rengjør og klargjøre dataene
Uansett hvor vi har fått dataene våre , det kan være noen ting galt med det som vi trenger å korrigere for å forberede det for KNN-algoritmen. Dataene kan for eksempel ikke være i det formatet algoritmen forventer, eller det kan være manglende verdier som vi bør fylle ut eller fjerne fra dataene før vi sender dem inn i algoritmen.
Vår KNN-implementering ovenfor er avhengig på strukturerte data. Det må være i tabellformat. I tillegg antar implementeringen at alle kolonnene inneholder numeriske data, og at den siste kolonnen i dataene våre har etiketter som vi kan utføre en eller annen funksjon på. Så uansett hvor vi har dataene våre, må vi sørge for at de samsvarer med disse begrensningene.
Dataene nedenfor er et eksempel på hva våre rensede data kan ligne på. Dataene inneholder tretti filmer, inkludert data for hver film i syv sjangre og deres IMDB-rangeringer. Etikettkolonnen har alle nuller fordi vi ikke bruker dette datasettet til klassifisering eller regresjon.
I tillegg er det forhold mellom filmene som ikke blir tatt hensyn til (f.eks. skuespillere, regissører og temaer) når du bruker KNN-algoritmen bare fordi dataene som fanger disse forholdene mangler i datasettet. Når vi kjører KNN-algoritmen på dataene våre, vil likheten utelukkende være basert på de medfølgende sjangrene og IMDB-klassifiseringen av filmene.
Bruk algoritmen
Se for deg et øyeblikk . Vi navigerer på MoviesXb-nettstedet, en fiktiv IMDb-spin-off, og vi møter The Post. Vi er ikke sikre på at vi vil se på det, men sjangrene fascinerer oss; vi er nysgjerrige på andre lignende filmer. Vi blar ned til «More Like This» -delen for å se hvilke anbefalinger MoviesXb vil gi, og de algoritmiske tannhjulene begynner å snu.
MoviesXb-nettstedet sender en forespørsel til back-enden for de 5 filmene som ligner mest på The Post. Back-enden har et anbefalt datasett nøyaktig som vårt. Det begynner med å lage radrepresentasjonen (bedre kjent som en funksjonsvektor) for The Post, så kjører den et program som ligner på det nedenfor for å søk etter de 5 filmene som ligner mest på The Post, og send til slutt resultatene tilbake til MoviesXb-nettstedet.
Når vi kjører dette programmet, ser vi at MoviesXb anbefaler 12 Years A Slave, Hacksaw Ridge, Queen of Katwe, The Wind Rises, and A Beautiful Mind Nå som vi forstår fullt ut hvordan KNN-algoritmen fungerer, er vi i stand til å forklare nøyaktig hvordan KNN-algoritmen kom med disse anbefalingene. Gratulerer!
Sammendrag
K-near est neighbours (KNN) algoritme er en enkel, overvåket maskinlæringsalgoritme som kan brukes til å løse både klassifiserings- og regresjonsproblemer. Det er enkelt å implementere og forstå, men har en stor ulempe ved å bli betydelig tregere etter hvert som størrelsen på dataene som er i bruk vokser.
KNN fungerer ved å finne avstandene mellom et spørsmål og alle eksemplene i dataene, velge de spesifiserte talleksemplene (K) nærmest spørringen, og deretter stemme på den hyppigste etiketten (i tilfelle klassifisering) eller gjennomsnittlig etikettene (i tilfelle regresjon).
I tilfelle klassifisering og regresjon, så vi at valg av riktig K for dataene våre gjøres ved å prøve flere Ks og velge den som fungerer best.
Til slutt så vi på et eksempel på hvordan KNN-algoritmen kunne brukes i anbefalingssystemer, en applikasjon av KNN-søk.