k-Nearest Neighbors (KNN) 알고리즘은 두 가지 분류를 모두 해결하는 데 사용할 수있는 간단하고 구현하기 쉬운지도 머신 러닝 알고리즘입니다. 회귀 문제. 중지! 압축을 풀겠습니다.

지도 형 머신 러닝 알고리즘 (비지 도형 머신 러닝 알고리즘과 반대)은 라벨이 지정된 입력 데이터를 사용하여 레이블이 지정되지 않은 새로운 데이터가 주어 졌을 때 적절한 출력을 생성하는 함수를 배웁니다.
컴퓨터가 어린이이고, 우리가 감독자 (예 : 부모, 보호자 또는 교사)이며, 어린이 (컴퓨터)를 원한다고 상상해보십시오. 돼지가 어떻게 생겼는지 배우기 위해 우리는 어린이에게 몇 가지 다른 사진을 보여줄 것입니다. 그 중 일부는 돼지이고 나머지는 어떤 것이 든 (고양이, 개 등)의 사진 일 수 있습니다.
돼지를 보면 “돼지!”라고 외칩니다. 돼지가 아니면 “아니, 돼지가 아니야!”라고 외칩니다. 아이와 함께이 일을 여러 번 한 후 사진을 보여주고 “돼지?”라고 묻습니다. 그리고 그들은 정확하게 (대부분의 경우) “돼지!”라고 말할 것입니다. 또는 “아니, 돼지가 아니야!” 이것이 바로 감독 형 머신 러닝입니다.

지도 형 머신 러닝 알고리즘은 분류 또는 회귀 문제를 해결하는 데 사용됩니다.
분류 문제에는 출력으로 이산 값이 있습니다. 예를 들어 “피자에 파인애플을 좋아함”과 “피자에 파인애플을 좋아하지 않음”은 불 연속적입니다. 중간 지대가 없습니다. 어린이에게 돼지를 식별하도록 가르치는 위의 비유는 분류 문제의 또 다른 예입니다.

이 이미지는 분류 데이터의 기본 예를 보여줍니다. 예측 자 (또는 예측 자 집합)와 레이블이 있습니다. 이미지에서 우리는 누군가의 나이 (예측 자)를 기준으로 피자에서 파인애플 (1)을 좋아하는지 (0) 여부를 예측하려고 할 수 있습니다.
출력을 나타내는 것은 표준 관행입니다 ( label)을 1, -1 또는 0과 같은 정수로 표시합니다.이 경우이 숫자는 순전히 표현입니다. 그렇게하는 것은 의미가 없기 때문에 수학적 연산을 수행해서는 안됩니다. 잠시 생각해보십시오. “파인애플을 좋아함”+ “파인애플을 좋아하지 않음”은 무엇입니까? 바로 그거죠. 우리는 그것들을 더할 수 없기 때문에 그들의 숫자 표현을 더해서는 안됩니다.
회귀 문제는 출력으로 실수 (소수점이있는 숫자)를 가지고 있습니다. 예를 들어 아래 표의 데이터를 사용하여 키에 따른 체중을 추정 할 수 있습니다.
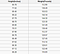
회귀 분석에 사용되는 데이터는 위 이미지에 표시된 데이터와 유사합니다. 독립 변수 (또는 독립 변수 집합)와 종속 변수 (독립 변수가 주어지면 추측하려는 것)가 있습니다. 예를 들어 높이는 독립 변수이고 무게는 종속 변수라고 말할 수 있습니다.
또한 각 행은 일반적으로 예, 관측치 또는 데이터 포인트라고하며 각 열 (라벨 / 종속 변수)는 종종 예측 변수, 차원, 독립 변수 또는 특성이라고합니다.
비지도 머신 러닝 알고리즘은 레이블없이 입력 데이터를 사용합니다. 즉, 교사 (레이블)가 어린이에게 알려주지 않습니다. (컴퓨터) 그것이 맞을 때 또는 실수를하여 스스로 고칠 수있을 때.
새로운 라벨이없는 데이터가 주어지면 예측을 할 수있는 기능을 배우려는지도 학습과는 다릅니다. , 비지도 학습은 데이터에 대한 더 많은 통찰력을 제공하기 위해 데이터의 기본 구조를 학습하려고합니다.
K-Nearest Neighbors
KNN 알고리즘은 유사한 항목이 가까운 곳에 존재한다고 가정합니다. . 즉, 비슷한 것들이 서로 가까이에 있습니다.
“깃털의 새들이 모여 듭니다.”

위 이미지에서 대부분의 경우 유사한 데이터 포인트가 서로 가깝다는 점에 유의하세요. KNN 알고리즘은 알고리즘이 유용 할만큼 충분히 사실이라는 가정에 달려 있습니다. KNN은 우리가 어린 시절에 배웠을 수있는 몇 가지 수학 (그래프에서 점 사이의 거리 계산)을 통해 유사성 (거리, 근접성 또는 근접성이라고도 함)에 대한 아이디어를 포착합니다.
참고 : 계속 진행하기 전에 그래프에서 점 사이의 거리를 계산해야합니다. 이 계산이 수행되는 방법에 대해 잘 모르거나 복습이 필요한 경우 “2 점 사이의 거리”전체를 꼼꼼히 읽고 바로 돌아 오십시오.
다른 방법으로 거리를 계산할 수 있습니다. 방법은 우리가 해결하는 문제에 따라 더 바람직 할 수 있습니다. 그러나 직선 거리 (유클리드 거리라고도 함)는 인기 있고 친숙한 선택입니다.
KNN 알고리즘
- 데이터로드
- 선택한 수의 이웃으로 K 초기화
3. 데이터의 각 예에 대해
3.1 계산 데이터에서 쿼리 예제와 현재 예제 사이의 거리
3.2 정렬 된 컬렉션에 예제의 거리와 색인 추가
4. 정렬 된 거리 컬렉션을 정렬하고 가장 작은 것부터 가장 큰 것 (오름차순)으로 거리 별 인덱스
5. 정렬 된 컬렉션에서 처음 K 개 항목 선택
6. 선택한 K 개 항목의 레이블 가져 오기
5. p>
7. 회귀면 ret urn K 레이블의 평균
8. 분류 인 경우 K 레이블의 모드를 반환합니다.
KNN 구현 (처음부터)
K에 적합한 값 선택
데이터에 적합한 K를 선택하기 위해 KNN 알고리즘을 다음과 같이 여러 번 실행합니다. K의 다른 값을 선택하고 이전에 본 적이없는 데이터가 주어 졌을 때 정확하게 예측하는 알고리즘의 능력을 유지하면서 발생하는 오류 수를 줄이는 K를 선택합니다.
다음은 유지해야 할 몇 가지 사항입니다. mind :
- K 값을 1로 줄이면 예측의 안정성이 떨어집니다. 잠시 생각해보십시오. K = 1이고 여러 개의 빨간색과 하나의 녹색으로 둘러싸인 쿼리 지점이 있지만 (위의 색상 그림의 왼쪽 상단 모서리에 대해 생각하고 있습니다) 녹색은 가장 가까운 이웃 하나입니다. 합리적으로 쿼리 지점이 빨간색 일 가능성이 가장 높지만 K = 1이기 때문에 KNN은 쿼리 지점이 녹색이라고 잘못 예측합니다.
- 반대로 K 값을 늘리면 예측이 더 많아집니다. 다수의 투표 / 평균화로 인해 안정적이므로 더 정확한 예측을 할 가능성이 더 높습니다 (특정 지점까지). 결국 우리는 점점 더 많은 오류를 목격하기 시작합니다. 이 시점에서 우리는 K의 값을 너무 많이 밀었다는 것을 압니다.
- 라벨 중에서 과반수 투표 (예 : 분류 문제에서 모드 선택)를하는 경우에는 일반적으로 K를 만듭니다. 타이 브레이커가있는 홀수입니다.
장점
- 알고리즘은 간단하고 구현하기 쉽습니다.
- 필요하지 않습니다. 모델을 구축하거나 여러 매개 변수를 조정하거나 추가로 가정합니다.
- 알고리즘은 다재다능합니다. 분류, 회귀 및 검색에 사용할 수 있습니다 (다음 섹션에서 설명).
단점
- 알고리즘은 다음과 같이 상당히 느려집니다. 예제 및 / 또는 예측 변수 / 독립 변수의 수가 증가합니다.
실제 KNN
KNN의 주요 단점은 데이터 볼륨이 증가함에 따라 상당히 느려집니다. 신속하게 예측해야하는 환경에서는 비현실적인 선택입니다. 또한 더 정확한 분류 및 회귀 결과를 생성 할 수있는 더 빠른 알고리즘이 있습니다.
그러나 예측을 수행하는 데 사용하는 데이터를 신속하게 처리 할 수있는 충분한 컴퓨팅 리소스가 있다면 KNN은 여전히 해결에 유용 할 수 있습니다. 유사한 개체 식별에 의존하는 솔루션이있는 문제. 이에 대한 예는 KNN-search의 응용 프로그램 인 추천 시스템에서 KNN 알고리즘을 사용하는 것입니다.
Recommender Systems
대규모에서 이것은 Amazon에서 제품을 추천하는 것처럼 보입니다. Medium, Netflix의 영화 또는 YouTube의 비디오. 하지만 처리하는 데이터의 양이 엄청 나기 때문에 모두가 더 효율적인 추천 수단을 사용한다고 확신 할 수 있습니다.
그러나 우리가 가지고있는 것을 사용하여 이러한 추천 시스템 중 하나를 더 작은 규모로 복제 할 수 있습니다. 이 기사에서 배웠습니다. 영화 추천 시스템의 핵심을 구축합시다.
어떤 질문에 답하려고합니까?
영화 데이터 세트를 고려할 때 영화 검색어와 가장 유사한 5 개의 영화는 무엇입니까?
영화 데이터 수집
Netflix, Hulu 또는 IMDb에서 일했다면 데이터웨어 하우스에서 데이터를 가져올 수 있습니다. 우리는 이러한 회사에서 일하지 않기 때문에 다른 방법을 통해 데이터를 가져와야합니다. UCI Machine Learning Repository, IMDb의 데이터 세트에서 일부 영화 데이터를 사용하거나 직접 만들 수 있습니다.
데이터 탐색, 정리 및 준비
데이터를 얻은 모든 곳에서 , KNN 알고리즘을 준비하기 위해 수정해야하는 문제가있을 수 있습니다. 예를 들어 데이터가 알고리즘이 예상하는 형식이 아니거나 데이터를 알고리즘에 파이프하기 전에 데이터에서 채우거나 제거해야하는 누락 된 값이있을 수 있습니다.
위의 KNN 구현은 구조화 된 데이터. 테이블 형식이어야합니다. 또한 구현에서는 모든 열에 숫자 데이터가 포함되어 있고 데이터의 마지막 열에 일부 기능을 수행 할 수있는 레이블이 있다고 가정합니다. 따라서 데이터를 어디에서 가져 왔든 이러한 제약 조건을 준수해야합니다.
아래 데이터는 정리 된 데이터가 닮은 예입니다. 이 데이터에는 7 개 장르의 각 영화에 대한 데이터와 해당 IMDB 등급을 포함하여 30 편의 영화가 포함됩니다. 분류 또는 회귀에이 데이터 세트를 사용하지 않기 때문에 라벨 열에는 모두 0이 있습니다.
또한 설명되지 않는 영화간에 관계가 있습니다 (예 : 배우, 감독 및 테마) KNN 알고리즘을 사용할 때 단순히 이러한 관계를 캡처하는 데이터가 데이터 세트에서 누락 되었기 때문입니다. 따라서 데이터에 대해 KNN 알고리즘을 실행할 때 유사성은 포함 된 장르와 영화의 IMDB 등급만을 기반으로합니다.
알고리즘 사용
잠시 동안 상상해보세요. . 가상의 IMDb 스핀 오프 인 MoviesXb 웹 사이트를 탐색하고 있으며 The Post를 만나게됩니다. 우리는 그것을보고 싶은지 확신 할 수 없지만 그 장르는 우리를 흥미롭게합니다. 다른 비슷한 영화가 궁금합니다. “More Like This”섹션까지 아래로 스크롤하여 MoviesXb의 권장 사항을 확인하고 알고리즘 기어가 시작됩니다.
MoviesXb 웹 사이트는 5 개의 영화에 대한 요청을 백엔드로 보냅니다. The Post와 가장 유사합니다. 백엔드에는 우리와 똑같은 추천 데이터 세트가 있습니다. The Post에 대한 행 표현 (특징 벡터로 더 잘 알려져 있음)을 생성하는 것으로 시작하여 다음과 유사한 프로그램을 실행합니다. The Post와 가장 유사한 5 개의 영화를 검색하고 결과를 MoviesXb 웹 사이트로 다시 보냅니다.
이 프로그램을 실행할 때 MoviesXb는 노예 12 년, Hacksaw Ridge, Katwe의 여왕, The Wind Rises, A Beautiful Mind를 권장합니다. . 이제 KNN 알고리즘의 작동 방식을 완전히 이해 했으므로 KNN 알고리즘이 이러한 권장 사항을 어떻게 만들 었는지 정확하게 설명 할 수 있습니다. 축하합니다!
요약
K-near est neighbours (KNN) 알고리즘은 분류 및 회귀 문제를 모두 해결하는 데 사용할 수있는 단순하고 감독되는 기계 학습 알고리즘입니다. 구현하고 이해하기는 쉽지만 사용중인 데이터의 크기가 커짐에 따라 상당히 느려지는 큰 단점이 있습니다.
KNN은 쿼리와 데이터의 모든 예제 사이의 거리를 찾는 방식으로 작동합니다. 쿼리에 가장 가까운 지정된 숫자 예 (K)를 선택한 다음 가장 빈번한 레이블 (분류의 경우)에 투표하거나 레이블의 평균을 계산합니다 (회귀의 경우).
분류 및 회귀 분석을 통해 데이터에 적합한 K를 선택하는 것은 여러 K를 시도하고 가장 잘 작동하는 K를 선택하여 수행되는 것을 확인했습니다.
마지막으로 KNN 알고리즘을 사용할 수있는 방법의 예를 살펴 보았습니다. 추천 시스템에서 KNN-search의 응용 프로그램입니다.