k最近傍(KNN)アルゴリズムは、両方の分類を解決するために使用できる、シンプルで実装が簡単な教師あり機械学習アルゴリズムです。および回帰問題。一時停止!開梱しましょう。

監視対象の機械学習アルゴリズム(監視対象外の機械学習アルゴリズムではなく)は、ラベル付けされた入力データに依存するものです。ラベルのない新しいデータが与えられたときに適切な出力を生成する関数を学習します。
コンピューターが子供であり、私たちがそのスーパーバイザー(親、保護者、教師など)であり、子供(コンピューター)が必要だとします。豚がどのように見えるかを学ぶために。子供にいくつかの異なる写真を見せます。そのうちのいくつかは豚で、残りは何でも(猫、犬など)の写真です。
豚を見ると、「豚!」と叫びます。豚じゃないときは「いや、豚じゃない!」と叫びます。これを子供と数回行った後、私たちは彼らに写真を見せて「豚?」と尋ねます。そして彼らは正しく(ほとんどの場合)「豚!」と言うでしょう。または「いいえ、豚ではありません!」写真が何であるかによって異なります。これは教師あり機械学習です。

教師あり機械学習アルゴリズムを使用して、分類または回帰の問題を解決します。
分類問題の出力には、離散値があります。たとえば、「ピザのパイナップルが好き」と「ピザのパイナップルが嫌い」は個別です。妥協点はありません。豚を識別するように子供に教えるという上記の例えは、分類問題のもう1つの例です。

この画像は、分類データがどのように見えるかの基本的な例を示しています。予測子(または予測子のセット)とラベルがあります。この画像では、年齢(予測子)に基づいて、誰かがパイナップル(1)をピザに好むかどうか(0)を予測しようとしている可能性があります。
出力を表すのが標準的な方法です( 1、-1、0などの整数としての分類アルゴリズムのラベル)。この場合、これらの数値は純粋に表現的なものです。それらに対して数学演算を実行することは無意味であるため、実行しないでください。ちょっと考えてみてください。 「パイナップルが好き」+「パイナップルが嫌い」とは何ですか?丁度。それらを追加することはできないため、数値表現を追加しないでください。
回帰問題では、出力として実数(小数点付きの数値)が使用されます。たとえば、次の表のデータを使用して、身長を考慮して誰かの体重を推定できます。
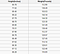
回帰分析で使用されるデータは、上の画像に示されているデータのようになります。独立変数(または独立変数のセット)と従属変数(独立変数が与えられたときに推測しようとしているもの)があります。たとえば、高さは独立変数であり、重みは従属変数であると言えます。
また、各行は通常、例、観測値、またはデータポイントと呼ばれ、各列(ラベル/は含まれません)従属変数)は、予測変数、次元、独立変数、または特徴と呼ばれることがよくあります。
教師なし機械学習アルゴリズムは、ラベルなしで入力データを使用します。つまり、教師(ラベル)が子供に指示することはありません。 (コンピューター)正しい場合、または自己修正できるように間違いを犯した場合。
新しいラベルのないデータが与えられた場合に予測を行うことができる関数を学習しようとする教師なし学習とは異なります。 、教師なし学習は、データの基本構造を学習して、データへの洞察を深めようとします。
K最近傍法
KNNアルゴリズムは、同様のものが近接して存在することを前提としています。 。言い換えれば、似たようなものが互いに近くにあります。
「羽の鳥が群がります。”

上の画像では、ほとんどの場合、類似したデータポイントが互いに近接していることに注意してください。 KNNアルゴリズムは、アルゴリズムが有用であるために十分に真実であるというこの仮定に依存します。 KNNは、子供の頃に学んだ可能性のあるいくつかの数学との類似性(距離、近接、または近さと呼ばれることもあります)の概念をキャプチャします。グラフ上の点間の距離を計算します。
注:私たちがどのように理解しているか先に進む前に、グラフ上のポイント間の距離を計算する必要があります。この計算方法に慣れていないか、復習が必要な場合は、「2点間の距離」全体をよく読んで、すぐに戻ってください。
距離を計算する方法は他にもありますが、1つは解決する問題によっては、方法が望ましい場合がありますが、直線距離(ユークリッド距離とも呼ばれます)は、一般的でよく知られている選択肢です。
KNNアルゴリズム
- データをロードする
- 選択した数の近傍にKを初期化します
3。データ内の各例について
3.1計算します。クエリの例とデータからの現在の例との間の距離。
3.2順序付けられたコレクションに例の距離とインデックスを追加します
4。距離の順序付けられたコレクションを並べ替えて距離の小さいものから大きいものへのインデックス(昇順)
5。並べ替えられたコレクションから最初のKエントリを選択します
6。選択したKエントリのラベルを取得します
p>
7.回帰の場合、ret Kラベルの平均をurn
8。分類する場合は、Kラベルのモードを返します
KNN実装(最初から)
Kの適切な値の選択
データに適切なKを選択するために、KNNアルゴリズムを数回実行します。 Kの値を変えて、これまでに見たことのないデータが与えられたときにアルゴリズムが正確に予測を行う能力を維持しながら、発生するエラーの数を減らすKを選択します。
以下の点に注意してください。 mind:
- Kの値を1に減らすと、予測の安定性が低下します。ちょっと考えてみてください。K= 1を想像してください。クエリポイントがいくつかの赤と1つの緑で囲まれています(上の色付きのプロットの左上隅について考えています)が、緑は1つの最近傍です。当然のことながら、クエリポイントは赤である可能性が高いと思われますが、K = 1であるため、KNNはクエリポイントが緑であると誤って予測します。
- 逆に、Kの値を大きくすると、予測はより多くなります。多数決/平均化により安定しているため、より正確な予測を行う可能性が高くなります(特定のポイントまで)。最終的に、私たちはますます多くのエラーを目撃し始めます。この時点で、Kの値を押しすぎていることがわかります。
- ラベル間で過半数の投票を行う場合(分類問題でモードを選択するなど)、通常はKを作成しますタイブレーカーを使用するには奇数です。
利点
- アルゴリズムはシンプルで実装が簡単です。
- 必要はありません。モデルを構築したり、いくつかのパラメーターを調整したり、追加の仮定を行ったりします。
- アルゴリズムは多用途です。分類、回帰、および検索に使用できます(次のセクションで説明します)。
短所
- アルゴリズムは、次のように大幅に遅くなります。例および/または予測子/独立変数の数が増加します。
実際のKNN
データの量が増えると大幅に遅くなるというKNNの主な欠点により、予測を迅速に行う必要がある環境では、非現実的な選択です。さらに、より正確な分類と回帰の結果を生成できるより高速なアルゴリズムがあります。
ただし、予測に使用するデータを迅速に処理するのに十分なコンピューティングリソースがあれば、KNNは解決に役立ちます。類似のオブジェクトの識別に依存する解決策がある問題。この例は、KNN検索のアプリケーションであるレコメンダーシステムでKNNアルゴリズムを使用することです。
レコメンダーシステム
大規模な場合、これはAmazonで製品を推奨するように見えます。ミディアム、Netflixの映画、またはYouTubeのビデオ。ただし、処理するデータの量が膨大なため、すべてがより効率的な推奨手段を使用していることは確かです。
ただし、これらの推奨システムの1つを、私たちが持っているものを使用して小規模に複製することはできます。この記事でここで学びました。映画レコメンダーシステムのコアを構築しましょう。
どのような質問に答えようとしていますか?
映画データセットを前提として、映画クエリに最も類似した5つの映画は何ですか?
映画データを収集します。
Netflix、Hulu、またはIMDbで働いていた場合、それらのデータウェアハウスからデータを取得できます。これらの企業では働いていないため、他の方法でデータを取得する必要があります。 UCI Machine Learning Repositoryの一部の映画データやIMDbのデータセットを使用することも、独自のデータセットを入念に作成することもできます。
データの調査、クリーンアップ、準備
データを取得した場所、KNNアルゴリズムの準備のために修正する必要がある、いくつかの問題がある可能性があります。たとえば、データがアルゴリズムで期待される形式でない場合や、データをアルゴリズムにパイプする前にデータに入力または削除する必要のある値が欠落している場合があります。
上記のKNN実装は依存しています。構造化データについて。表形式である必要があります。さらに、実装では、すべての列に数値データが含まれ、データの最後の列に何らかの機能を実行できるラベルが含まれていることを前提としています。したがって、どこからデータを取得した場合でも、これらの制約に準拠させる必要があります。
以下のデータは、クリーンアップされたデータがどのように見えるかの例です。データには、7つのジャンルにわたる各映画のデータとそのIMDBレーティングを含む、30本の映画が含まれています。このデータセットを分類または回帰に使用していないため、ラベル列はすべてゼロになります。
さらに、映画間には考慮されない関係があります(俳優、監督、テーマ)KNNアルゴリズムを使用する場合、それらの関係をキャプチャするデータがデータセットから欠落しているという理由だけで。したがって、データに対してKNNアルゴリズムを実行すると、類似性は、含まれているジャンルと映画のIMDB評価のみに基づいて決定されます。
アルゴリズムを使用する
少し想像してみてください。 。架空のIMDbスピンオフであるMoviesXbWebサイトをナビゲートしているときに、ThePostに遭遇します。見たいかどうかはわかりませんが、そのジャンルに興味をそそられます。私たちは他の同様の映画に興味があります。 [More Like This]セクションまで下にスクロールして、MoviesXbが行う推奨事項を確認し、アルゴリズムのギアが回転し始めます。
MoviesXb Webサイトは、バックエンドに5本の映画のリクエストを送信します。バックエンドには、私たちとまったく同じ推奨データセットがあります。これは、投稿の行表現(特徴ベクトルとしてよく知られています)を作成することから始まり、次に次のようなプログラムを実行します。 The Postに最も類似している5つの映画を検索し、最終的に結果をMoviesXbWebサイトに送り返します。
このプログラムを実行すると、MoviesXbが12 Years A Slave、Hacksaw Ridge、Queen of Katwe、The Wind Rises、およびA BeautifulMindを推奨していることがわかります。 。KNNアルゴリズムがどのように機能するかを完全に理解したので、KNNアルゴリズムがこれらの推奨事項を作成するようになった経緯を正確に説明できます。おめでとうございます!
概要
k-near est neighbors(KNN)アルゴリズムは、分類と回帰の両方の問題を解決するために使用できる、単純な教師あり機械学習アルゴリズムです。実装と理解は簡単ですが、使用中のデータのサイズが大きくなると大幅に遅くなるという大きな欠点があります。
KNNは、クエリとデータ内のすべての例の間の距離を見つけることで機能します。クエリに最も近い指定された数の例(K)を選択してから、最も頻度の高いラベルに投票するか(分類の場合)、ラベルを平均します(回帰の場合)。
の場合分類と回帰では、データに適切なKを選択するには、いくつかのKを試し、最も効果的なKを選択する必要があることがわかりました。
最後に、KNNアルゴリズムの使用例を確認しました。レコメンダーシステムでは、KNN検索のアプリケーション。