Lalgoritmo k-Nearest Neighbors (KNN) è un algoritmo di apprendimento automatico supervisionato semplice e facile da implementare che può essere utilizzato per risolvere entrambe le classificazioni e problemi di regressione. Pausa! Cerchiamo di scompattarlo.

Un algoritmo di apprendimento automatico supervisionato (al contrario di un algoritmo di apprendimento automatico non supervisionato) è uno che si basa su dati di input etichettati per apprendere una funzione che produce un output appropriato quando vengono forniti nuovi dati senza etichetta.
Immagina che un computer sia un bambino, noi siamo il suo supervisore (ad es. genitore, tutore o insegnante) e vogliamo che il bambino (computer) per sapere che aspetto ha un maiale. Mostreremo al bambino diverse immagini, alcune delle quali sono maiali e le altre potrebbero essere immagini di qualsiasi cosa (gatti, cani, ecc.).
Quando vediamo un maiale, gridiamo “maiale!” Quando non è un maiale, gridiamo “no, non maiale!” Dopo averlo fatto diverse volte con il bambino, mostriamo loro una foto e chiediamo “maiale?” e diranno correttamente (la maggior parte delle volte) “maiale!” o “no, non maiale!” a seconda di quale sia limmagine. Questo è lapprendimento automatico supervisionato.

Gli algoritmi di apprendimento automatico supervisionato vengono utilizzati per risolvere problemi di classificazione o regressione.
Un problema di classificazione ha un valore discreto come output. Ad esempio, “gli piace lananas sulla pizza” e “non gli piace lananas sulla pizza” sono discreti. Non cè via di mezzo. Lanalogia sopra di insegnare a un bambino a identificare un maiale è un altro esempio di un problema di classificazione.

Questa immagine mostra un esempio di base di come potrebbero apparire i dati di classificazione. Abbiamo un predittore (o un insieme di predittori) e unetichetta. Nellimmagine, potremmo provare a prevedere se a qualcuno piace o meno lananas (1) sulla sua pizza o meno (0) in base alla sua età (il predittore).
È prassi standard rappresentare loutput ( label) di un algoritmo di classificazione come un numero intero come 1, -1 o 0. In questo caso, questi numeri sono puramente rappresentativi. Non si dovrebbero eseguire operazioni matematiche su di essi perché farlo non avrebbe senso. Pensa per un momento. Cosa significa “gli piace lananas” + “non piace lananas”? Esattamente. Non possiamo aggiungerli, quindi non dovremmo aggiungere le loro rappresentazioni numeriche.
Un problema di regressione ha un numero reale (un numero con un punto decimale) come output. Ad esempio, potremmo utilizzare i dati nella tabella seguente per stimare il peso di qualcuno data la sua altezza.
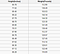
I dati utilizzati in unanalisi di regressione saranno simili ai dati mostrati nellimmagine sopra. Abbiamo una variabile indipendente (o un insieme di variabili indipendenti) e una variabile dipendente (la cosa che stiamo cercando di indovinare date le nostre variabili indipendenti). Ad esempio, potremmo dire che laltezza è la variabile indipendente e il peso è la variabile dipendente.
Inoltre, ogni riga è in genere chiamata esempio, osservazione o punto dati, mentre ogni colonna (esclusa letichetta / variabile dipendente) è spesso chiamato predittore, dimensione, variabile indipendente o caratteristica.
Un algoritmo di apprendimento automatico senza supervisione utilizza i dati di input senza alcuna etichetta, in altre parole, nessun insegnante (etichetta) lo dice al bambino (computer) quando è corretto o quando ha commesso un errore in modo che possa correggersi da solo.
A differenza dellapprendimento supervisionato che cerca di apprendere una funzione che ci permetterà di fare previsioni dati alcuni nuovi dati senza etichetta , lapprendimento senza supervisione cerca di apprendere la struttura di base dei dati per darci una visione più approfondita dei dati.
K-Nearest Neighbors
Lalgoritmo KNN presume che cose simili esistano nelle immediate vicinanze . In altre parole, cose simili sono vicine luna allaltra.
“Uccelli di una piuma si radunano insieme.”

Nota nellimmagine sopra che la maggior parte delle volte, punti dati simili sono vicini tra loro. Lalgoritmo KNN si basa su questo presupposto che è abbastanza vero perché lalgoritmo sia utile. KNN cattura lidea di somiglianza (a volte chiamata distanza, prossimità o vicinanza) con alcuni calcoli che potremmo aver imparato nella nostra infanzia, calcolando la distanza tra i punti su un grafico.
Nota: una comprensione di come noi calcolare la distanza tra i punti su un grafico è necessario prima di proseguire. Se non hai familiarità o hai bisogno di un aggiornamento su come viene eseguito questo calcolo, leggi attentamente “Distanza tra 2 punti” nella sua interezza e torna subito indietro.
Ci sono altri modi per calcolare la distanza, e uno potrebbe essere preferibile a seconda del problema che stiamo risolvendo. Tuttavia, la distanza in linea retta (chiamata anche distanza euclidea) è una scelta popolare e familiare.
Lalgoritmo KNN
- Carica i dati
- Inizializza K sul numero di vicini scelto
3. Per ogni esempio nei dati
3.1 Calcola il distanza tra lesempio di query e lesempio corrente dai dati.
3.2 Aggiungere la distanza e lindice dellesempio a una raccolta ordinata
4. Ordinare la raccolta ordinata di distanze e indici dal più piccolo al più grande (in ordine crescente) in base alle distanze
5. Scegli le prime K voci dalla raccolta ordinata
6. Ottieni le etichette delle K voci selezionate
7. Se la regressione, ret urn la media delle etichette K
8. Se la classificazione, restituisce la modalità delle etichette K
Limplementazione KNN (da zero)
Scelta del valore corretto per K
Per selezionare la K giusta per i tuoi dati, eseguiamo lalgoritmo KNN più volte con diversi valori di K e scegli la K che riduce il numero di errori che incontriamo mantenendo la capacità dellalgoritmo di fare previsioni accurate quando gli vengono forniti dati che non ha visto prima.
Ecco alcune cose da tenere in considerazione mente:
- Man mano che riduciamo il valore di K a 1, le nostre previsioni diventano meno stabili. Pensa solo per un minuto, immagina K = 1 e abbiamo un punto di query circondato da diversi rossi e uno verde (sto pensando allangolo in alto a sinistra del grafico colorato sopra), ma il verde è lunico vicino più vicino. Ragionevolmente, potremmo pensare che il punto della query sia molto probabilmente rosso, ma poiché K = 1, KNN predice erroneamente che il punto della query è verde.
- Al contrario, aumentando il valore di K, le nostre previsioni diventano più stabile grazie al voto a maggioranza / media e, quindi, più propenso a fare previsioni più accurate (fino a un certo punto). Alla fine, iniziamo a testimoniare un numero crescente di errori. È a questo punto che sappiamo di aver spinto troppo oltre il valore di K.
- Nei casi in cui stiamo prendendo un voto di maggioranza (ad esempio scegliendo la modalità in un problema di classificazione) tra le etichette, di solito facciamo K un numero dispari per avere un tiebreak.
Vantaggi
- Lalgoritmo è semplice e facile da implementare.
- Non è necessario costruire un modello, regolare diversi parametri o formulare ipotesi aggiuntive.
- Lalgoritmo è versatile. Può essere utilizzato per la classificazione, la regressione e la ricerca (come vedremo nella sezione successiva).
Svantaggi
- Lalgoritmo diventa notevolmente più lento il numero di esempi e / o predittori / variabili indipendenti aumenta.
KNN in pratica
Il principale svantaggio di KNN di diventare significativamente più lento allaumentare del volume dei dati lo rende un scelta impraticabile in ambienti in cui le previsioni devono essere fatte rapidamente. Inoltre, ci sono algoritmi più veloci che possono produrre risultati di classificazione e regressione più accurati.
Tuttavia, a condizione che tu abbia risorse di calcolo sufficienti per gestire rapidamente i dati che stai utilizzando per fare previsioni, KNN può ancora essere utile per risolvere problemi che hanno soluzioni che dipendono dallidentificazione di oggetti simili. Un esempio di ciò è lutilizzo dellalgoritmo KNN nei sistemi di raccomandazione, unapplicazione di ricerca KNN.
Sistemi di raccomandazione
Su larga scala, sembrerebbe raccomandare prodotti su Amazon, articoli su Medium, film su Netflix o video su YouTube. Tuttavia, possiamo essere certi che tutti usano mezzi più efficienti per formulare raccomandazioni a causa dellenorme volume di dati che elaborano.
Tuttavia, potremmo replicare uno di questi sistemi di raccomandazione su scala più piccola usando ciò che abbiamo imparato qui in questo articolo. Cerchiamo di costruire il nucleo di un sistema di raccomandazione di film.
A quale domanda stiamo cercando di rispondere?
Dato il nostro set di dati sui film, quali sono i 5 film più simili a una query di film?
Raccogliere i dati sui film
Se lavorassimo per Netflix, Hulu o IMDb, potremmo prendere i dati dal loro data warehouse. Poiché non lavoriamo in nessuna di queste aziende, dobbiamo ottenere i nostri dati con altri mezzi. Potremmo utilizzare i dati di alcuni film dal repository UCI Machine Learning, il set di dati di IMDb o crearne uno nostro.
Esplora, pulisci e prepara i dati
Ovunque abbiamo ottenuto i nostri dati , potrebbero esserci alcune cose sbagliate che dobbiamo correggere per prepararlo per lalgoritmo KNN. Ad esempio, i dati potrebbero non essere nel formato previsto dallalgoritmo oppure potrebbero esserci valori mancanti che dovremmo riempire o rimuovere dai dati prima di reindirizzarli nellalgoritmo.
La nostra implementazione KNN sopra si basa su dati strutturati. Deve essere in un formato tabella. Inoltre, limplementazione presuppone che tutte le colonne contengano dati numerici e che lultima colonna dei nostri dati abbia etichette su cui possiamo eseguire alcune funzioni. Quindi, ovunque abbiamo ottenuto i nostri dati, dobbiamo renderli conformi a questi vincoli.
I dati seguenti sono un esempio di come potrebbero somigliare i nostri dati puliti. I dati contengono trenta film, inclusi i dati per ogni film in sette generi e le loro valutazioni IMDB. La colonna delle etichette ha tutti zeri perché non stiamo utilizzando questo set di dati per la classificazione o la regressione.
Inoltre, ci sono relazioni tra i film che non saranno prese in considerazione (ad es. attori, registi e temi) quando si utilizza lalgoritmo KNN semplicemente perché i dati che acquisiscono tali relazioni mancano dal set di dati. Di conseguenza, quando eseguiamo lalgoritmo KNN sui nostri dati, la somiglianza si baserà esclusivamente sui generi inclusi e sulle classificazioni IMDB dei film.
Usa lalgoritmo
Immagina per un momento . Stiamo navigando nel sito web di MoviesXb, uno spin-off immaginario di IMDb, e incontriamo The Post. Non siamo sicuri di volerlo vedere, ma i suoi generi ci incuriosiscono; siamo curiosi di altri film simili. Scorriamo verso il basso fino alla sezione “Più simili a questo” per vedere quali consigli fornirà MoviesXb e gli ingranaggi algoritmici iniziano a girare.
Il sito web di MoviesXb invia una richiesta al suo back-end per i 5 film che sono molto simili a The Post. Il back-end ha un set di dati di raccomandazione esattamente come il nostro. Inizia creando la rappresentazione di riga (meglio nota come vettore di funzionalità) per The Post, quindi esegue un programma simile a quello qui sotto per cerca i 5 film più simili a The Post e infine invia i risultati al sito web di MoviesXb.
Quando eseguiamo questo programma, vediamo che MoviesXb consiglia 12 Years A Slave, Hacksaw Ridge, Queen of Katwe, The Wind Rises e A Beautiful Mind . Ora che abbiamo compreso appieno come funziona lalgoritmo KNN, siamo in grado di spiegare esattamente come lalgoritmo KNN è arrivato a formulare questi consigli. Congratulazioni!
Riepilogo
Il k-near Lalgoritmo est neighbors (KNN) è un algoritmo di apprendimento automatico semplice e supervisionato che può essere utilizzato per risolvere problemi di classificazione e regressione. È facile da implementare e da capire, ma ha il grosso svantaggio di rallentare notevolmente con laumentare della dimensione dei dati in uso.
KNN funziona trovando le distanze tra una query e tutti gli esempi nei dati, selezionando il numero di esempi specificato (K) più vicino alla query, quindi vota letichetta più frequente (nel caso della classificazione) o calcola la media delle etichette (nel caso della regressione).
Nel caso di classificazione e regressione, abbiamo visto che la scelta della K corretta per i nostri dati viene eseguita provando diverse K e scegliendo quella che funziona meglio.
Infine, abbiamo esaminato un esempio di come potrebbe essere utilizzato lalgoritmo KNN nei sistemi di raccomandazione, unapplicazione di KNN-search.