A k-legközelebbi szomszédok (KNN) algoritmus egy egyszerű, egyszerűen megvalósítható felügyelt gépi tanulási algoritmus, amely mindkét osztályozás megoldására használható. és regressziós problémák. Szünet! Csomagoljuk ki ezt. div>
Képzelje el, hogy a számítógép gyermek, mi vagyunk a felügyelője (pl. szülő, gyám vagy tanár), és szeretnénk, ha a gyermek (számítógép) megtanulni, hogy néz ki egy disznó. Több különböző képet mutatunk a gyereknek, amelyek közül néhány disznó, a többi pedig bármiről (macskákról, kutyákról stb.) Készült kép.
Ha disznót látunk, azt kiáltjuk, hogy “disznó!” Ha nem disznó, azt kiáltjuk, hogy “nem, nem disznó!” Miután ezt többször megtettük a gyerekkel, megmutatunk nekik egy képet, és megkérdezzük: “disznó?” és helyesen (legtöbbször) azt mondják, hogy “disznó!” vagy “nem, nem disznó!” attól függően, hogy mi a kép. Ez a felügyelt gépi tanulás. “>
A felügyelt gépi tanulási algoritmusokat osztályozási vagy regressziós problémák megoldására használják.
A besorolási problémának diszkrét értéke van. Például: “szereti az ananászt a pizzán” és “nem szereti az ananászt a pizzán” diszkrét. Nincs középút. A fenti analógia, amely szerint a gyermeket disznó azonosítására tanítják, egy másik példa az osztályozási problémára.

Ez a kép egy alapvető példát mutat be arra, hogy milyenek lehetnek az osztályozási adatok. Van prediktorunk (vagy prediktorkészletünk) és egy címkénk. A képen megpróbálhatjuk megjósolni, hogy valaki szereti-e az ananászt (1) a pizzáján, vagy sem (0) az életkora (a prediktor) alapján.
Szokásos gyakorlat a kimenet ábrázolása ( osztályozási algoritmus egész számként, például 1, -1 vagy 0. Ebben az esetben ezek a számok pusztán reprezentatívak. Matematikai műveleteket nem szabad végrehajtani rajtuk, mert így értelmetlen lenne. Gondolj egy pillanatra. Mi az, hogy “szereti az ananászt” + “nem szereti az ananászt”? Pontosan. Nem adhatjuk hozzá őket, ezért ne adjuk hozzá a numerikus reprezentációikat.
A regressziós probléma valós számmal (tizedes ponttal rendelkező számmal) rendelkezik. Például az alábbi táblázat adatai alapján megbecsülhetjük valaki súlyát, figyelembe véve a magasságát.
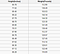
A regresszióanalízis során használt adatok hasonlóak lesznek a fenti képen látható adatokhoz. Van egy független változónk (vagy független változók halmaza) és egy függő változónk (az a dolog, amit a független változóinkkal próbálunk kitalálni). Például azt mondhatnánk, hogy a magasság a független változó, a súly pedig a függő változó.
Ezenkívül minden sort szokás példának, megfigyelésnek vagy adatpontnak nevezni, míg az egyes oszlopokat (a címkét / függő változó) gyakran nevezik prediktornak, dimenziónak, független változónak vagy szolgáltatásnak.
Egy felügyelet nélküli gépi tanulási algoritmus a bemeneti adatokat címkék nélkül használja fel, más szavakkal, nincs tanár (címke), amely elmondja a gyermeknek (számítógép), amikor helyes vagy ha hibát követett el, hogy önkorrigálhasson.
Ellentétben a felügyelt tanulással, amely megpróbál olyan funkciót megtanulni, amely lehetővé teszi számunkra, hogy előrejelzéseket adjunk néhány új, címkézetlen adat alapján , a felügyelet nélküli tanulás megpróbálja megtanulni az adatok alapvető szerkezetét, hogy jobban betekintést nyerhessünk az adatokba.
K-Legközelebbi szomszédok
A KNN algoritmus feltételezi, hogy hasonló dolgok léteznek közvetlen közelében . Más szavakkal, hasonló dolgok vannak közel egymáshoz.
“Egy madár madarak özönlenek.”

A fenti képen vegye figyelembe, hogy legtöbbször hasonló adatpontok vannak közel egymáshoz. A KNN algoritmus függ attól, hogy ez a feltételezés elég igaz-e ahhoz, hogy az algoritmus hasznos legyen. A KNN megragadja a hasonlóság gondolatát (néha távolságnak, közelségnek vagy közelségnek hívják) néhány matematikával, amelyet gyermekkorunkban megtanultunk – kiszámítva a pontok közötti távolságot egy grafikonon.
Megjegyzés: Megértés arról, hogyan a továbbjutás előtt ki kell számítani a grafikon pontjai közötti távolságot. Ha nem ismeri, vagy frissítésre szorul a számítás módja, olvassa el alaposan a „2 pont közötti távolság” egészét, és jöjjön vissza.
A távolság kiszámításának más módjai is vannak, és egy Az általunk megoldott problémától függően előnyösebb lehet az út, de az egyenes távolság (más néven euklideszi távolság) népszerű és ismerős választás.
A KNN algoritmus
- Töltse be az adatokat
- Inicializálja K-t a kiválasztott szomszédok számához
3. Az adatokban szereplő minden példa esetében
3.1 Számítsa ki az távolság a lekérdezési példa és az aktuális példa között az adatoktól.
3.2 Adja hozzá a példa távolságát és indexét egy rendezett gyűjteményhez
4. Rendezze a sorrendbe vett távolságok gyűjteményét és indexek a legkisebbtől a legnagyobbig (növekvő sorrendben) a távolságok szerint
5. Válassza ki az első K bejegyzést a rendezett gyűjteményből
6. Szerezze be a kijelölt K bejegyzések címkéit
7. Ha regresszió, akkor újból urnálja a K címkék átlagát
8. Besorolás esetén adja vissza a K címkék módját.
A KNN megvalósítása (a semmiből)
A K megfelelő értékének kiválasztása
Az adatokhoz megfelelő K kiválasztásához többször futtatjuk a KNN algoritmust a különböző K értékeket, és válassza ki azt a K értéket, amely csökkenti a hibák számát, miközben megőrzi az algoritmus képességét a pontos előrejelzésekre, amikor olyan adatokat ad meg, amelyeket még nem látott.
Íme néhány dolog, amit érdemes betartani elme:
- Amint csökkentjük a K értékét 1-re, jóslataink kevésbé stabilak lesznek. Gondolkodjon csak el egy percig, képzelje el, hogy K = 1, és van egy lekérdezési pontunk, amelyet több piros és egy zöld vesz körül (a fenti színes telek bal felső sarkára gondolok), de a zöld az egyetlen legközelebbi szomszéd. Ésszerűen azt gondolnánk, hogy a lekérdezés pontja valószínűleg piros, de mivel K = 1, a KNN helytelenül jósolja, hogy a lekérdezési pont zöld.
- Ezzel ellentétben, ahogy növeljük a K értékét, jóslataink egyre inkább stabil a többségi szavazás / átlagolás miatt, és így nagyobb valószínűséggel fog pontosabb előrejelzéseket tenni (egy bizonyos pontig). Végül egyre több hibának lehetünk tanúi. Ezen a ponton tudjuk, hogy túl messzire toltuk a K értékét.
- Azokban az esetekben, amikor a címkék között többségi szavazatot veszünk (pl. A besorolási probléma módját választjuk), általában K páratlan szám, hogy legyen tiebreaker.
Előnyök
- Az algoritmus egyszerű és egyszerűen megvalósítható.
- Nincs szükség készítsen modellt, hangoljon több paramétert, vagy tegyen további feltételezéseket.
- Az algoritmus sokoldalú. Használható osztályozáshoz, regresszióhoz és kereséshez (amint azt a következő szakaszban láthatjuk).
Hátrányok
- Az algoritmus jelentősen lassabb lesz a példák és / vagy a prediktorok / független változók száma növekszik.
KNN a gyakorlatban
A KNN fő hátránya, hogy jelentősen lassabbá válik, mivel az adatok mennyisége növekszik. nem praktikus választás olyan környezetekben, ahol gyors előrejelzéseket kell meghozni. Sőt, vannak olyan gyorsabb algoritmusok, amelyek pontosabb osztályozási és regressziós eredményeket képesek előállítani.
Ha azonban elegendő számítási erőforrással rendelkezik az előrejelzésekhez használt adatok gyors kezeléséhez, a KNN továbbra is hasznos lehet a megoldásban problémák, amelyeknek megoldásaik hasonló objektumok azonosításától függenek. Erre példa a KNN algoritmus használata az ajánló rendszerekben, a KNN-keresés alkalmazása.
Ajánló rendszerek
Ez nagymértékben úgy néz ki, mintha termékeket ajánlana az Amazon-on, cikkeket a Közepes, filmek a Netflix-en vagy videók a YouTube-on. Bár biztosak lehetünk benne, hogy mindannyian hatékonyabb módszereket alkalmaznak az ajánlások megfogalmazására az általuk feldolgozott óriási adatmennyiség miatt.
Mindazonáltal ezeknek az ajánló rendszereknek az egyikét kisebb méretben megismételhetnénk megtanulta itt, ebben a cikkben. Építsük fel a filmek ajánló rendszerének magját.
Milyen kérdésre próbálunk válaszolni?
A filmek adatsora alapján mi az 5 filmhez leginkább hasonló film?
Filmadatok gyűjtése
Ha a Netflixnél, a Hulunál vagy az IMDb-nél dolgoznánk, megragadhatnánk az adatokat az adattárházukból. Mivel egyik vállalatnál sem dolgozunk, más módon kell megszereznünk adatainkat. Használhatnánk néhány filmet az UCI Machine Learning Repository-ból, az IMDb adatsorából, vagy alaposan létrehozhatnánk a sajátunkat.
Fedezze fel, tisztítsa meg és készítse elő az adatokat
Bárhonnan is szereztük be adatainkat , lehetnek olyan dolgok, amelyek hibát okoznak, és ezeket ki kell javítanunk a KNN algoritmus előkészítéséhez. Például előfordulhat, hogy az adatok nem abban a formátumban vannak, mint amire az algoritmus számít, vagy hiányozhatnak olyan értékek, amelyeket ki kell töltenünk vagy eltávolítanunk kell az adatokból, mielőtt az algoritmusba vezetnénk őket.
A fenti KNN megvalósításunk támaszkodik a strukturált adatokról. Táblázat formátumúnak kell lennie. Ezenkívül a megvalósítás feltételezi, hogy az összes oszlop számadatokat tartalmaz, és hogy az adataink utolsó oszlopának vannak olyan címkéi, amelyeken valamilyen funkciót elvégezhetünk. Tehát bárhonnan is hoztuk adatainkat, meg kell tennünk, hogy megfeleljenek ezeknek a korlátozásoknak.
Az alábbi adatok példák arra, hogy a megtisztított adataink milyenek lehetnek. Az adatok harminc filmet tartalmaznak, beleértve az egyes filmek adatait hét műfajban és azok IMDB-besorolásait. A címkék oszlopban minden nulla szerepel, mert nem ezt az adatsort használjuk osztályozáshoz vagy regresszióhoz.
Ezenkívül vannak olyan kapcsolatok a filmek között, amelyeket nem számolnak el (pl. színészek, rendezők és témák) a KNN algoritmus használatakor pusztán azért, mert az ezeket a kapcsolatokat rögzítő adatok hiányoznak az adatkészletből. Következésképpen, amikor az adatainkon futtatjuk a KNN algoritmust, a hasonlóság kizárólag a mellékelt műfajokon és a filmek IMDB besorolásán alapul.
Használja az algoritmust
Képzelje el egy pillanatra . Navigálunk a MoviesXb webhelyen, egy kitalált IMDb spin-off-on, és találkozunk a The Post-szal. Nem biztos, hogy meg akarjuk nézni, de műfajai érdekeltek; kíváncsiak vagyunk más hasonló filmekre. Görgessünk le a “Több hasonló” szakaszig, hogy megnézzük, milyen ajánlásokat fog tenni a MoviesXb, és az algoritmikus sebességváltó fordulni kezd.
A MoviesXb webhely kérést küld a hátlapjára az 5 film megtekintésére. a legjobban hasonlítanak a The Post-hoz. A háttér egy ajánlási adatkészlettel rendelkezik, pontosan úgy, mint a miénk. Ez azzal kezdődik, hogy létrehozza a The Post sor ábrázolását (ismertebb nevén szolgáltatásvektor), majd az alábbihoz hasonló programot futtat keresse meg az 5 filmet, amelyek leginkább hasonlítanak a The Post-hoz, és végül visszaküldi az eredményeket a MoviesXb webhelyére.
A program futtatásakor azt látjuk, hogy a MoviesXb 12 éves rabszolgát, Hacksaw Ridge-t, Katwe királynőjét, a szél kelését és egy gyönyörű elmét ajánlja Most, hogy teljesen megértettük a KNN algoritmus működését, pontosan meg tudjuk magyarázni, hogy a KNN algoritmus miként adta meg ezeket az ajánlásokat. Gratulálunk!
Összefoglalás
A k-közeli Az est szomszédok (KNN) algoritmus egy egyszerű, felügyelt gépi tanulási algoritmus, amely mind osztályozási, mind regressziós problémák megoldására használható. Könnyű megvalósítani és megérteni, de jelentős hátránya, hogy jelentősen lassul, mivel a használatban lévő adatok mérete növekszik.
A KNN úgy működik, hogy megtalálja a távolságot egy lekérdezés és az adatok összes példája között, kiválasztva a lekérdezéshez legközelebb eső megadott példákat (K), majd a leggyakoribb címkére szavaz (osztályozás esetén), vagy átlagolja a címkéket (regresszió esetén).
osztályozás és regresszió alapján azt láttuk, hogy a megfelelő K kiválasztása az adatainkhoz több K használatával történik, és kiválasztja azt, amelyik a legjobban működik.
Végül megvizsgáltunk egy példát arra, hogyan lehetne használni a KNN algoritmust ajánló rendszerekben a KNN-keresés alkalmazása.