Lalgorithme des k-plus proches voisins (KNN) est un algorithme dapprentissage automatique supervisé simple et facile à mettre en œuvre qui peut être utilisé pour résoudre les deux classifications et les problèmes de régression. Pause! Décompressons cela.

Un algorithme dapprentissage automatique supervisé (par opposition à un algorithme dapprentissage automatique non supervisé) repose sur des données dentrée étiquetées pour apprendre une fonction qui produit une sortie appropriée lorsquon lui donne de nouvelles données non étiquetées.
Imaginez quun ordinateur est un enfant, nous sommes son superviseur (par exemple, parent, tuteur ou enseignant), et nous voulons lenfant (ordinateur) pour savoir à quoi ressemble un cochon. Nous montrerons à lenfant plusieurs images différentes, dont certaines sont des cochons et le reste pourrait être des photos de nimporte quoi (chats, chiens, etc.).
Quand nous voyons un cochon, nous crions « cochon! » Quand ce n’est pas un cochon, on crie « non, pas cochon! » Après avoir fait cela plusieurs fois avec lenfant, nous leur montrons une photo et demandons « cochon? » et ils diront correctement (la plupart du temps) « cochon! » ou « non, pas cochon! » en fonction de limage. Il sagit de lapprentissage automatique supervisé.

Les algorithmes dapprentissage automatique supervisé sont utilisés pour résoudre les problèmes de classification ou de régression.
Un problème de classification a une valeur discrète en sortie. Par exemple, «aime lananas sur la pizza» et «naime pas lananas sur la pizza» sont discrets. Il ny a pas de juste milieu. Lanalogie ci-dessus consistant à apprendre à un enfant à identifier un porc est un autre exemple de problème de classification.

Cette image montre un exemple de base de ce à quoi pourraient ressembler les données de classification. Nous avons un prédicteur (ou un ensemble de prédicteurs) et une étiquette. Dans limage, nous essayons peut-être de prédire si quelquun aime lananas (1) sur sa pizza ou non (0) en fonction de son âge (le prédicteur).
Il est courant de représenter le résultat ( label) dun algorithme de classification sous la forme dun nombre entier tel que 1, -1 ou 0. Dans ce cas, ces nombres sont purement représentatifs. Les opérations mathématiques ne devraient pas être effectuées sur eux car cela naurait aucun sens. Réfléchissez un instant. Quest-ce que « aime lananas » + « naime pas lananas »? Exactement. Nous ne pouvons pas les ajouter, donc nous ne devons pas ajouter leurs représentations numériques.
Un problème de régression a un nombre réel (un nombre avec un point décimal) comme sortie. Par exemple, nous pourrions utiliser les données du tableau ci-dessous pour estimer le poids dune personne compte tenu de sa taille.
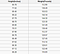
Les données utilisées dans une analyse de régression ressembleront aux données présentées dans limage ci-dessus. Nous avons une variable indépendante (ou un ensemble de variables indépendantes) et une variable dépendante (ce que nous essayons de deviner étant donné nos variables indépendantes). Par exemple, nous pourrions dire que la hauteur est la variable indépendante et que le poids est la variable dépendante.
De plus, chaque ligne est généralement appelée un exemple, une observation ou un point de données, tandis que chaque colonne (sans inclure létiquette / variable dépendante) est souvent appelée prédicteur, dimension, variable indépendante ou caractéristique.
Un algorithme dapprentissage automatique non supervisé utilise des données dentrée sans aucune étiquette – en dautres termes, aucun enseignant (étiquette) ne le dit à lenfant (ordinateur) quand il a raison ou quand il a fait une erreur pour quil puisse sauto-corriger.
Contrairement à lapprentissage supervisé qui essaie dapprendre une fonction qui nous permettra de faire des prédictions à partir de nouvelles données non étiquetées , lapprentissage non supervisé essaie dapprendre la structure de base des données pour nous donner plus dinformations sur les données.
K-Nearest Neighbours
Lalgorithme KNN suppose que des choses similaires existent à proximité . En dautres termes, des choses similaires sont proches les unes des autres.
« Les oiseaux dune plume sassemblent.”

Notez dans limage ci-dessus que la plupart du temps, des points de données similaires sont proches les uns des autres. Lalgorithme KNN repose sur le fait que cette hypothèse est suffisamment vraie pour que lalgorithme soit utile. KNN capture lidée de similitude (parfois appelée distance, proximité ou proximité) avec certaines mathématiques que nous aurions pu apprendre dans notre enfance – calcul de la distance entre les points dun graphique.
Remarque: une compréhension de la façon dont nous calculer la distance entre les points sur un graphique est nécessaire avant de passer à autre chose. Si vous ne connaissez pas ou avez besoin dun rappel sur la façon dont ce calcul est effectué, lisez attentivement « Distance entre 2 points » dans son intégralité et revenez immédiatement.
Il existe dautres méthodes de calcul de distance, et une peut être préférable selon le problème que nous résolvons. Cependant, la distance en ligne droite (également appelée distance euclidienne) est un choix populaire et familier.
Lalgorithme KNN
- Chargez les données
- Initialisez K sur le nombre de voisins que vous avez choisi
3. Pour chaque exemple dans les données
3.1 Calculez le distance entre lexemple de requête et lexemple courant à partir des données.
3.2 Ajouter la distance et lindex de lexemple à une collection ordonnée
4. Trier la collection ordonnée de distances et indices du plus petit au plus grand (par ordre croissant) par les distances
5. Choisissez les K premières entrées de la collection triée
6. Obtenez les étiquettes des K entrées sélectionnées
7. Si régression, ret urn la moyenne des K étiquettes
8. Si classification, retournez le mode des K labels
Limplémentation KNN (à partir de zéro)
Choisir la bonne valeur pour K
Pour sélectionner le K qui convient à vos données, nous exécutons lalgorithme KNN plusieurs fois avec différentes valeurs de K et choisissez le K qui réduit le nombre derreurs que nous rencontrons tout en conservant la capacité de lalgorithme à faire des prédictions avec précision quand on lui donne des données quil na pas vues auparavant.
Voici quelques choses à garder esprit:
- À mesure que nous diminuons la valeur de K à 1, nos prédictions deviennent moins stables. Pensez juste une minute, imaginez K = 1 et nous avons un point de requête entouré de plusieurs rouges et un vert (je pense au coin supérieur gauche du graphique coloré ci-dessus), mais le vert est le seul voisin le plus proche. Raisonnablement, nous pensons que le point de requête est très probablement rouge, mais comme K = 1, KNN prédit à tort que le point de requête est vert.
- À linverse, à mesure que nous augmentons la valeur de K, nos prédictions deviennent plus stable en raison du vote majoritaire / de la moyenne, et donc plus susceptible de faire des prédictions plus précises (jusquà un certain point). Finalement, nous commençons à assister à un nombre croissant derreurs. Cest à ce stade que nous savons que nous avons poussé la valeur de K trop loin.
- Dans les cas où nous prenons un vote majoritaire (par exemple en choisissant le mode dans un problème de classification) parmi les étiquettes, nous faisons généralement K un nombre impair pour avoir une égalité.
Avantages
- Lalgorithme est simple et facile à implémenter.
- Il nest pas nécessaire de construire un modèle, régler plusieurs paramètres ou faire des hypothèses supplémentaires.
- Lalgorithme est polyvalent. Il peut être utilisé pour la classification, la régression et la recherche (comme nous le verrons dans la section suivante).
Inconvénients
- Lalgorithme devient beaucoup plus lent à mesure que le nombre dexemples et / ou de prédicteurs / variables indépendantes augmente.
KNN en pratique
Le principal inconvénient de KNN est de devenir significativement plus lent à mesure que le volume de données augmente en fait un choix peu pratique dans des environnements où les prévisions doivent être faites rapidement. De plus, il existe des algorithmes plus rapides qui peuvent produire des résultats de classification et de régression plus précis.
Cependant, à condition que vous disposiez de ressources informatiques suffisantes pour gérer rapidement les données que vous utilisez pour faire des prédictions, KNN peut toujours être utile pour résoudre problèmes dont les solutions dépendent de lidentification dobjets similaires. Un exemple de ceci est lutilisation de lalgorithme KNN dans les systèmes de recommandation, une application de KNN-search.
Systèmes de recommandation
À grande échelle, cela ressemblerait à recommander des produits sur Amazon, des articles sur Medium, films sur Netflix ou vidéos sur YouTube. Cependant, nous pouvons être certains quils utilisent tous des moyens plus efficaces de faire des recommandations en raison de lénorme volume de données quils traitent.
Cependant, nous pourrions reproduire lun de ces systèmes de recommandation à plus petite échelle en utilisant ce que nous avons appris ici dans cet article. Construisons le noyau dun système de recommandation de films.
À quelle question essayons-nous de répondre?
Compte tenu de notre ensemble de données de films, quels sont les 5 films les plus similaires à une requête de film?
Rassemblez des données de films
Si nous travaillions chez Netflix, Hulu ou IMDb, nous pourrions récupérer les données de leur entrepôt de données. Étant donné que nous ne travaillons dans aucune de ces entreprises, nous devons obtenir nos données par d’autres moyens. Nous pourrions utiliser certaines données de films du référentiel UCI Machine Learning, lensemble de données dIMDb, ou créer minutieusement les nôtres.
Explorer, nettoyer et préparer les données
Partout où nous avons obtenu nos données , il peut y avoir des problèmes que nous devons corriger pour le préparer pour lalgorithme KNN. Par exemple, les données peuvent ne pas être au format attendu par lalgorithme, ou il peut y avoir des valeurs manquantes que nous devrions remplir ou supprimer des données avant de les envoyer dans lalgorithme.
Notre implémentation KNN ci-dessus repose sur sur des données structurées. Il doit être au format tableau. En outre, limplémentation suppose que toutes les colonnes contiennent des données numériques et que la dernière colonne de nos données a des étiquettes sur lesquelles nous pouvons effectuer certaines fonctions. Donc, doù que nous obtenions nos données, nous devons les rendre conformes à ces contraintes.
Les données ci-dessous sont un exemple de ce à quoi nos données nettoyées pourraient ressembler. Les données contiennent trente films, y compris des données pour chaque film dans sept genres et leurs classements IMDB. La colonne des libellés contient tous des zéros, car nous nutilisons pas cet ensemble de données pour la classification ou la régression.
De plus, certaines relations entre les films ne seront pas prises en compte (par exemple, les thèmes) lors de lutilisation de lalgorithme KNN simplement parce que les données qui capturent ces relations sont absentes de lensemble de données. Par conséquent, lorsque nous exécutons lalgorithme KNN sur nos données, la similitude sera basée uniquement sur les genres inclus et les notes IMDB des films.
Utilisez lalgorithme
Imaginez un instant . Nous naviguons sur le site Web MoviesXb, une spin-off fictive dIMDb, et nous rencontrons The Post. Nous ne sommes pas sûrs de vouloir le regarder, mais ses genres nous intriguent; nous sommes curieux de découvrir dautres films similaires. Nous faisons défiler jusquà la section « Plus comme ça » pour voir quelles recommandations MoviesXb fera, et les engrenages algorithmiques commencent à tourner.
Le site Web MoviesXb envoie une demande à son back-end pour les 5 films qui sont les plus similaires à The Post. Le back-end a un ensemble de données de recommandation exactement comme le nôtre. Il commence par créer la représentation de ligne (mieux connue sous le nom de vecteur dentités) pour The Post, puis il exécute un programme similaire à celui ci-dessous pour recherchez les 5 films qui ressemblent le plus à The Post et renvoie enfin les résultats sur le site MoviesXb.
Lorsque nous exécutons ce programme, nous voyons que MoviesXb recommande 12 Years A Slave, Hacksaw Ridge, Queen of Katwe, The Wind Rises, and A Beautiful Mind . Maintenant que nous comprenons parfaitement comment fonctionne lalgorithme KNN, nous sommes en mesure dexpliquer exactement comment lalgorithme KNN en est venu à faire ces recommandations. Félicitations!
Résumé
Le k-near Lalgorithme est voisins (KNN) est un algorithme dapprentissage automatique simple et supervisé qui peut être utilisé pour résoudre des problèmes de classification et de régression. Il est facile à mettre en œuvre et à comprendre, mais présente linconvénient majeur de ralentir considérablement à mesure que la taille des données utilisées augmente.
KNN fonctionne en trouvant les distances entre une requête et tous les exemples dans les données, sélectionner le nombre dexemples spécifié (K) le plus proche de la requête, puis vote pour létiquette la plus fréquente (dans le cas de la classification) ou fait la moyenne des étiquettes (dans le cas de la régression).
Dans le cas de classification et régression, nous avons vu que choisir le bon K pour nos données se fait en essayant plusieurs K et en choisissant celui qui fonctionne le mieux.
Enfin, nous avons regardé un exemple de la façon dont lalgorithme KNN pourrait être utilisé dans les systèmes de recommandation, une application de KNN-search.