k-lähimpien naapureiden (KNN) -algoritmi on yksinkertainen, helposti toteutettava valvottu koneoppimisalgoritmi, jota voidaan käyttää molempien luokitusten ratkaisemiseen ja regressio-ongelmat. Tauko! Pura tämä pakkaus.

Valvottu koneoppimisalgoritmi (toisin kuin valvomaton koneoppimisalgoritmi) on sellainen, joka perustuu merkittyihin syötetietoihin oppia funktio, joka tuottaa sopivan ulostulon, kun hänelle annetaan uusia merkitsemättömiä tietoja.
Kuvittele, että tietokone on lapsi, olemme sen valvoja (esim. vanhempi, huoltaja tai opettaja) ja haluamme lapsen (tietokoneen) oppia miltä sika näyttää. Näytämme lapselle useita erilaisia kuvia, joista osa on sikoja ja loput voivat olla kuvia kaikesta (kissat, koirat jne.).
Kun näemme sian, huudamme ”sika!” Kun se ei ole sika, huudamme ”ei, ei sika!” Kun olemme tehneet tämän useita kertoja lapsen kanssa, näytämme heille kuvan ja kysymme ”sika?” ja he sanovat oikein (suurimman osan ajasta) ”sika!” tai ”ei, ei sika!” kuvan mukaan. Se on valvottu koneoppiminen.

Valvottuja koneoppimisalgoritmeja käytetään luokittelu- tai regressio-ongelmien ratkaisemiseen.
Luokitteluongelman tuotoksena on erillinen arvo. Esimerkiksi ”tykkää ananasta pizzassa” ja ”ei tykkää ananasta pizzassa” ovat erillisiä. Ei ole keskitietä. Yllä oleva analogia lapsen opettamisesta tunnistamaan sika on toinen esimerkki luokitusongelmasta.

Tässä kuvassa on perusesimerkki siitä, miltä luokitustiedot voivat näyttää. Meillä on ennustaja (tai ennustinsarja) ja etiketti. Kuvassa saatamme yrittää ennustaa tykkääkö joku ananasta (1) pizzassaan vai ei (0) iän (ennustajan) perusteella.
On tavallista edustaa tuotosta ( luokitusalgoritmin kokonaislukuna, kuten 1, -1 tai 0. Tässä tapauksessa nämä luvut ovat puhtaasti edustavia. Matemaattisia operaatioita ei pitäisi suorittaa heille, koska sen tekeminen olisi merkityksetöntä. Ajattele hetki. Mikä on ”tykkää ananasta” + ”ei tykkää ananasta”? Tarkalleen. Emme voi lisätä niitä, joten meidän ei pitäisi lisätä niiden numeerisia esityksiä.
Regressiotehtävän lähtö on reaaliluku (desimaalilukuinen luku). Voisimme esimerkiksi käyttää alla olevan taulukon tietoja arvioidaksemme jonkun painon korkeuden perusteella.
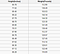
Regressioanalyysissä käytetyt tiedot näyttävät samanlaisilta kuin yllä olevassa kuvassa. Meillä on riippumaton muuttuja (tai joukko riippumattomia muuttujia) ja riippuva muuttuja (asia, jota yritämme arvata riippumattomien muuttujiemme perusteella). Voisimme esimerkiksi sanoa, että korkeus on itsenäinen muuttuja ja paino on riippuva muuttuja.
Jokaista riviä kutsutaan myös tyypillisesti esimerkiksi, havainnoksi tai datapisteeksi, kun taas jokaista saraketta (ilman tunnusta / riippuva muuttuja) kutsutaan usein ennustajaksi, ulottuvuudeksi, itsenäiseksi muuttujaksi tai ominaisuudeksi.
Valvomaton koneoppimisalgoritmi käyttää syötetietoja ilman tunnisteita – toisin sanoen, ei opettajaa (tunniste) kerro lapselle (tietokone), kun se on oikein tai kun se on tehnyt virheen, jotta se voi korjata itsensä.
Toisin kuin valvottu oppiminen, joka yrittää oppia toiminnon, jonka avulla voimme tehdä ennusteita antamalla uusia merkitsemättömiä tietoja , valvomaton oppiminen yrittää oppia tietojen perusrakenteen, jotta voimme saada enemmän tietoa tiedoista.
K-lähimmät naapurit
KNN-algoritmi olettaa, että samanlaisia asioita on lähellä . Toisin sanoen samanlaiset asiat ovat lähellä toisiaan.
”Höyhenen linnut parvevat yhdessä.”

Huomaa yllä olevassa kuvassa, että suurimmaksi osaksi samankaltaiset datapisteet ovat lähellä toisiaan. KNN-algoritmi riippuu siitä, että tämä oletus on riittävän totta, jotta algoritmista olisi hyötyä. KNN sieppaa ajatuksen samankaltaisuudesta (joskus kutsutaan etäisyydeksi, läheisyydeksi tai läheisyydeksi) joillakin matematiikoilla, jotka olemme saattaneet oppia lapsuudessamme – laskemalla pisteiden välinen etäisyys kaaviossa. laskea kaavion pisteiden välinen etäisyys on välttämätöntä ennen kuin jatkat. Jos et ole perehtynyt laskutoimituksiin tai haluat kertoa siitä, lue perusteellisesti 2 pisteen välinen etäisyys kokonaisuudessaan ja palaa takaisin.
Etäisyyden laskemiseen on muitakin tapoja, ja yksi tapa saattaa olla parempi ratkaisemamme ongelman mukaan. Suoraviivainen etäisyys (jota kutsutaan myös euklidiseksi etäisyydeksi) on kuitenkin suosittu ja tuttu valinta.
KNN-algoritmi
- Lataa tiedot
- Alusta K valitsemaasi naapureiden lukumäärään
3. Kunkin datan esimerkin osalta
3.1 Laske kyselyesimerkin ja nykyisen esimerkin välinen etäisyys tiedoista.
3.2 Lisää esimerkin etäisyys ja hakemisto järjestettyyn kokoelmaan
4. Lajittele järjestetty etäisyyksien kokoelma ja indeksit pienimmistä suurimpiin (nousevassa järjestyksessä) etäisyyksien mukaan
5. Valitse lajitellun kokoelman ensimmäiset K-merkinnät
6. Hanki valittujen K-merkintöjen tunnisteet
7. Jos regressio, palaa uudelleen urnaa K-tarrojen keskiarvo
8. Jos luokitellaan, palauta K-tarrojen tila.
KNN-toteutus (tyhjästä)
Oikean arvon valitseminen K: lle
Jos haluat valita tietoillesi sopivan K: n, suoritamme KNN-algoritmin useita kertoja eri K: n arvot ja valitse K, joka vähentää kohtaamiemme virheiden määrää samalla kun algoritmi kykenee tekemään ennusteita tarkasti, kun sille annetaan tietoja, joita se ei ole ennen nähnyt.
Tässä on joitain asioita, jotka kannattaa pitää sisällään mieli:
- Kun pienennämme K: n arvon arvoon 1, ennustuksemme muuttuvat vähemmän vakaiksi. Ajattele vain hetken, kuvittele K = 1, ja meillä on kyselypiste, jota ympäröi useita punaisia ja yksi vihreä (ajattelen yllä olevan värillisen juonen vasenta yläkulmaa), mutta vihreä on ainoa lähin naapuri. Kohtuullisesti luulemme, että kyselypiste on todennäköisesti punainen, mutta koska K = 1, KNN ennustaa väärin, että kyselypiste on vihreä.
- Käänteisesti, kun kasvatamme K: n arvoa, ennustuksemme muuttuvat vakaa enemmistöäänestyksen / keskiarvon laskun vuoksi ja siten todennäköisempää ennusteita (tiettyyn pisteeseen asti). Lopulta alamme todistaa yhä enemmän virheitä. Tässä vaiheessa tiedämme, että olemme työntäneet K: n arvon liian pitkälle.
- Tapauksissa, joissa äänestämme enemmistön (esim. Valitsemme luokitusongelman tilassa) tunnisteiden joukossa, teemme yleensä K pariton numero, jos sinulla on tiebreaker.
Edut
- Algoritmi on yksinkertainen ja helppo toteuttaa.
- Ei tarvitse rakenna malli, viritä useita parametreja tai tee lisäoletuksia.
- Algoritmi on monipuolinen. Sitä voidaan käyttää luokitteluun, regressioon ja hakuun (kuten näemme seuraavassa osassa).
Haitat
- Algoritmi hidastuu huomattavasti esimerkkien ja / tai ennustajien / riippumattomien muuttujien määrä kasvaa.
KNN käytännössä
KNN: n tärkein haittapuoli on, että se muuttuu huomattavasti hitaammaksi tiedon määrän kasvaessa tekee siitä epäkäytännöllinen valinta ympäristöissä, joissa ennusteet on tehtävä nopeasti. Lisäksi on olemassa nopeampia algoritmeja, jotka voivat tuottaa tarkempia luokittelu- ja regressiotuloksia.
Jos sinulla on kuitenkin riittävästi laskentaresursseja ennakoiden tekemiseen käyttämiesi tietojen nopeaan käsittelyyn, KNN voi silti olla hyödyllinen ratkaisussa ongelmat, joilla on ratkaisuja, jotka riippuvat samankaltaisten kohteiden tunnistamisesta. Esimerkki tästä on KNN-algoritmin käyttäminen suositussysteemeissä, KNN-haun sovellus.
Suosittelijajärjestelmät
Tämä näyttäisi mittakaavassa suosittelevan tuotteita Amazonissa, artikkeleita Medium, elokuvia Netflixissä tai videoita YouTubessa. Vaikka voimme olla varmoja, että ne kaikki käyttävät tehokkaampia tapoja antaa suosituksia heidän käsittelemänsä valtavan määrän tietojen vuoksi.
Voimme kuitenkin kopioida yhden näistä suositusjärjestelmistä pienemmässä mittakaavassa käyttämällä sitä, mitä meillä on oppinut täällä tässä artikkelissa. Rakennetaan elokuvien suosittelujärjestelmän ydin.
Mihin kysymykseen yritämme vastata?
Mitkä ovat elokuvakyselyyn vastaavimmat viisi elokuvaa elokuvien tietojoukon perusteella?
Kerää elokuvien tietoja
Jos työskentelisimme Netflixissä, Hulussa tai IMDb: ssä, voisimme napata tiedot heidän tietovarastostaan. Koska emme työskentele missään näistä yrityksistä, meidän on hankittava tietomme jollakin muulla tavalla. Voisimme käyttää joitain elokuvien tietoja UCI Machine Learning -tietovarastosta, IMDb: n tietojoukosta tai luoda huolellisesti omat.
Tutki, puhdista ja valmistele tietoja
Mistä olemme saaneet tietomme , siinä voi olla joitain vikoja, jotka meidän on korjattava valmistellaksemme sitä KNN-algoritmille. Esimerkiksi tiedot eivät välttämättä ole siinä muodossa kuin algoritmi odottaa, tai niistä voi olla puuttuvia arvoja, jotka meidän on täytettävä tai poistettava tiedoista ennen kuin siirrämme ne algoritmiin.
Yllä oleva KNN-toteutuksemme luottaa jäsenneltyihin tietoihin. Sen on oltava taulukon muodossa. Lisäksi toteutus olettaa, että kaikki sarakkeet sisältävät numeerista tietoa ja että tietojemme viimeisessä sarakkeessa on tarroja, joihin voimme suorittaa jonkin toiminnon. Joten mistä olemme saaneet tietomme, meidän on saatettava ne noudattamaan näitä rajoituksia.
Alla olevat tiedot ovat esimerkki siitä, mitä puhdistamamme tiedot saattavat muistuttaa. Tiedot sisältävät kolmekymmentä elokuvaa, mukaan lukien tiedot kustakin elokuvasta seitsemässä tyylilajissa ja niiden IMDB-luokitukset. Tunnisteet-sarakkeessa on kaikki nollat, koska emme käytä tätä tietojoukkoa luokitteluun tai regressioon.
Elokuvien välillä on lisäksi suhteita, joita ei oteta huomioon (esim. näyttelijät, ohjaajat ja teemat) käytettäessä KNN-algoritmia yksinkertaisesti siksi, että kyseiset suhteet kaappaavat tiedot puuttuvat tietojoukosta. Näin ollen kun käytämme KNN-algoritmia tietojemme kanssa, samankaltaisuus perustuu yksinomaan mukana oleviin genreihin ja elokuvien IMDB-luokituksiin.
Käytä algoritmia
Kuvittele hetkeksi . Olemme selaamassa MoviesXb-verkkosivustoa, kuvitteellista IMDb-spin-offia, ja kohtaamme Postin. Emme ole varmoja, haluammeko katsella sitä, mutta sen tyylilajit kiehtovat meitä; olemme uteliaita muista vastaavista elokuvista. Vieritään alaspäin ”Lisää näin” -osioon nähdäksesi, mitä suosituksia MoviesXb antaa, ja algoritmiset vaihteet alkavat kääntyä.
MoviesXb -verkkosivusto lähettää pyynnön takana olevalle viidelle elokuvalle. ovat eniten samanlaisia kuin Post. Taustalla on suositustiedot, jotka ovat täsmälleen samankaltaiset kuin meidän. Se alkaa luomalla Postille riviesitys (tunnetaan paremmin ominaisuusvektorina), ja sitten se suorittaa samanlaisen ohjelman kuin alla oleva etsi viittä elokuvaa, jotka ovat eniten samanlaisia kuin The Post, ja lähettää tulokset lopulta takaisin MoviesXb-verkkosivustolle.
Kun suoritamme tämän ohjelman, näemme, että MoviesXb suosittelee 12-vuotista orjaa, Hacksaw Ridgen, Katwen kuningatar, Tuuli nousee ja Kaunis mieli . Nyt kun olemme täysin ymmärtäneet KNN-algoritmin toiminnan, voimme selittää tarkalleen, kuinka KNN-algoritmi on antanut nämä suositukset. Onnittelut!
Yhteenveto
K-near est naapurit (KNN) -algoritmi on yksinkertainen, valvottu koneoppimisalgoritmi, jota voidaan käyttää sekä luokittelu- että regressio-ongelmien ratkaisemiseen. Se on helppo toteuttaa ja ymmärtää, mutta sillä on suuri haittapuoli siitä, että se hidastuu merkittävästi, kun käytössä olevan datan koko kasvaa.
KNN toimii etsimällä kyselyn ja kaikkien tietojen esimerkkien väliset etäisyydet, valitsemalla kyselyä lähinnä olevat määritetyt esimerkkiluvut (K), äänestää sitten yleisimpiä tunnisteita (luokituksen tapauksessa) tai keskimääriä tunnisteita (regressiotapauksessa).
Jos kyseessä on luokittelu ja regressio, huomasimme, että oikean K: n valinta tietoihimme tapahtuu kokeilemalla useita K: itä ja valitsemalla se, joka toimii parhaiten.
Lopuksi tarkastelimme esimerkkiä siitä, kuinka KNN-algoritmia voitaisiin käyttää suosittelijajärjestelmissä KNN-haun sovellus.