Der K-Nearest Neighbours (KNN) -Algorithmus ist ein einfacher, leicht zu implementierender Algorithmus für überwachtes maschinelles Lernen, mit dem beide Klassifizierungen gelöst werden können und Regressionsprobleme. Pause! Packen wir das aus.

Ein überwachter Algorithmus für maschinelles Lernen (im Gegensatz zu einem unbeaufsichtigten Algorithmus für maschinelles Lernen) basiert auf beschrifteten Eingabedaten Lernen Sie eine Funktion, die eine angemessene Ausgabe erzeugt, wenn Sie neue unbeschriftete Daten erhalten.
Stellen Sie sich vor, ein Computer ist ein Kind, wir sind sein Vorgesetzter (z. B. Eltern, Erziehungsberechtigte oder Lehrer) und wir möchten das Kind (Computer). um zu lernen, wie ein Schwein aussieht. Wir werden dem Kind verschiedene Bilder zeigen, von denen einige Schweine sind und der Rest Bilder von allem sein können (Katzen, Hunde usw.).
Wenn wir ein Schwein sehen, rufen wir „Schwein!“ Wenn es kein Schwein ist, rufen wir „Nein, kein Schwein!“ Nachdem wir dies mehrmals mit dem Kind gemacht haben, zeigen wir ihm ein Bild und fragen „Schwein?“ und sie werden richtig (meistens) „Schwein“ sagen! oder „nein, kein Schwein!“ Dies ist überwachtes maschinelles Lernen.

Überwachte Algorithmen für maschinelles Lernen werden verwendet, um Klassifizierungs- oder Regressionsprobleme zu lösen.
Ein Klassifizierungsproblem hat einen diskreten Wert als Ausgabe. Zum Beispiel sind „mag Ananas auf Pizza“ und „mag keine Ananas auf Pizza“ diskret. Es gibt keinen Mittelweg. Die obige Analogie, einem Kind beizubringen, ein Schwein zu identifizieren, ist ein weiteres Beispiel für ein Klassifizierungsproblem.

Dieses Bild zeigt ein grundlegendes Beispiel dafür, wie Klassifizierungsdaten aussehen könnten. Wir haben einen Prädiktor (oder eine Reihe von Prädiktoren) und eine Bezeichnung. Im Bild versuchen wir möglicherweise vorherzusagen, ob jemand Ananas (1) auf seiner Pizza mag oder nicht (0), basierend auf seinem Alter (dem Prädiktor).
Es ist Standardpraxis, die Ausgabe darzustellen ( label) eines Klassifizierungsalgorithmus als Ganzzahl wie 1, -1 oder 0. In diesem Fall sind diese Zahlen rein repräsentativ. Mathematische Operationen sollten nicht an ihnen durchgeführt werden, da dies bedeutungslos wäre. Denken Sie einen Moment nach. Was ist „mag Ananas“ + „mag keine Ananas“? Genau. Wir können sie nicht hinzufügen, daher sollten wir ihre numerischen Darstellungen nicht hinzufügen.
Ein Regressionsproblem hat eine reelle Zahl (eine Zahl mit einem Dezimalpunkt) als Ausgabe. Zum Beispiel könnten wir die Daten in der folgenden Tabelle verwenden, um das Gewicht einer Person aufgrund ihrer Größe zu schätzen.
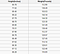
Die in einer Regressionsanalyse verwendeten Daten sehen ähnlich aus wie die im obigen Bild gezeigten Daten. Wir haben eine unabhängige Variable (oder eine Menge unabhängiger Variablen) und eine abhängige Variable (das, was wir angesichts unserer unabhängigen Variablen zu erraten versuchen). Zum Beispiel könnten wir sagen, dass Höhe die unabhängige Variable und Gewicht die abhängige Variable ist.
Außerdem wird jede Zeile normalerweise als Beispiel, Beobachtung oder Datenpunkt bezeichnet, während jede Spalte (ohne die Bezeichnung /) abhängige Variable) wird häufig als Prädiktor, Dimension, unabhängige Variable oder Merkmal bezeichnet.
Ein unbeaufsichtigter Algorithmus für maschinelles Lernen verwendet Eingabedaten ohne Beschriftung – mit anderen Worten, kein Lehrer (Beschriftung) sagt es dem Kind (Computer), wenn es richtig ist oder wenn es einen Fehler gemacht hat, damit es sich selbst korrigieren kann.
Im Gegensatz zu überwachtem Lernen, das versucht, eine Funktion zu erlernen, die es uns ermöglicht, Vorhersagen für einige neue unbeschriftete Daten zu treffen Beim unbeaufsichtigten Lernen wird versucht, die Grundstruktur der Daten zu lernen, um einen besseren Einblick in die Daten zu erhalten.
K-Nearest Neighbors
Der KNN-Algorithmus geht davon aus, dass ähnliche Dinge in unmittelbarer Nähe existieren . Mit anderen Worten, ähnliche Dinge sind nahe beieinander.
„Vögel einer Feder scharen sich zusammen.”

Beachten Sie im obigen Bild, dass ähnliche Datenpunkte die meiste Zeit nahe beieinander liegen. Der KNN-Algorithmus hängt davon ab, dass diese Annahme wahr genug ist, damit der Algorithmus nützlich ist. KNN erfasst die Idee der Ähnlichkeit (manchmal als Entfernung, Nähe oder Nähe bezeichnet) mit etwas Mathematik, die wir in unserer Kindheit gelernt haben könnten – Berechnung der Entfernung zwischen Punkten in einem Diagramm.
Hinweis: Ein Verständnis dafür, wie wir Berechnen Sie den Abstand zwischen Punkten in einem Diagramm, bevor Sie fortfahren. Wenn Sie mit dieser Berechnung nicht vertraut sind oder eine Auffrischung benötigen, lesen Sie „Abstand zwischen 2 Punkten“ vollständig durch und kehren Sie sofort zurück.
Es gibt andere Möglichkeiten zur Berechnung der Entfernung und eine Je nach dem Problem, das wir lösen, ist der Weg möglicherweise vorzuziehen. Die geradlinige Entfernung (auch als euklidische Entfernung bezeichnet) ist jedoch eine beliebte und bekannte Wahl.
Der KNN-Algorithmus
- Laden Sie die Daten
- Initialisieren Sie K auf die von Ihnen gewählte Anzahl von Nachbarn.
3. Berechnen Sie für jedes Beispiel in den Daten
3.1 die Abstand zwischen dem Abfragebeispiel und dem aktuellen Beispiel aus den Daten.
3.2 Fügen Sie den Abstand und den Index des Beispiels zu einer geordneten Sammlung hinzu.
4. Sortieren Sie die geordnete Sammlung von Entfernungen und Indizes vom kleinsten zum größten (in aufsteigender Reihenfolge) nach den Abständen
5. Wählen Sie die ersten K Einträge aus der sortierten Sammlung aus.
6. Holen Sie sich die Beschriftungen der ausgewählten K Einträge
7. Wenn Regression, ret Urnen Sie den Mittelwert der K-Bezeichnungen
8. Bei Klassifizierung den Modus der K-Labels zurückgeben
Die KNN-Implementierung (von Grund auf neu)
Auswahl des richtigen Werts für K
Um das für Ihre Daten geeignete K auszuwählen, führen wir den KNN-Algorithmus mehrmals mit aus verschiedene Werte von K und wählen Sie das K, das die Anzahl der Fehler verringert, auf die wir stoßen, während die Fähigkeit des Algorithmus erhalten bleibt, Vorhersagen genau zu treffen, wenn ihm Daten gegeben werden, die er zuvor noch nicht gesehen hat.
Hier sind einige Dinge zu beachten mind:
- Wenn wir den Wert von K auf 1 verringern, werden unsere Vorhersagen weniger stabil. Denken Sie nur eine Minute nach, stellen Sie sich K = 1 vor und wir haben einen Abfragepunkt, der von mehreren Rottönen und einem Grün umgeben ist (ich denke an die obere linke Ecke des farbigen Diagramms oben), aber das Grün ist der nächste Nachbar. Wir würden vernünftigerweise annehmen, dass der Abfragepunkt höchstwahrscheinlich rot ist, aber da K = 1 ist, sagt KNN fälschlicherweise voraus, dass der Abfragepunkt grün ist.
- Umgekehrt werden unsere Vorhersagen größer, wenn wir den Wert von K erhöhen stabil aufgrund der Mehrheitsentscheidung / -mittelung und daher wahrscheinlicher, genauere Vorhersagen zu treffen (bis zu einem bestimmten Punkt). Schließlich stellen wir eine zunehmende Anzahl von Fehlern fest. An diesem Punkt wissen wir, dass wir den Wert von K zu weit verschoben haben.
- In Fällen, in denen wir eine Mehrheitswahl (z. B. Auswahl des Modus bei einem Klassifizierungsproblem) unter den Labels treffen, machen wir normalerweise K. Eine ungerade Zahl für einen Tiebreaker.
Vorteile
- Der Algorithmus ist einfach und leicht zu implementieren.
- Es ist nicht erforderlich Erstellen Sie ein Modell, optimieren Sie mehrere Parameter oder treffen Sie zusätzliche Annahmen.
- Der Algorithmus ist vielseitig. Es kann zur Klassifizierung, Regression und Suche verwendet werden (wie wir im nächsten Abschnitt sehen werden).
Nachteile
- Der Algorithmus wird deutlich langsamer als Die Anzahl der Beispiele und / oder Prädiktoren / unabhängigen Variablen nimmt zu.
KNN in der Praxis
Der Hauptnachteil von KNN, mit zunehmendem Datenvolumen erheblich langsamer zu werden, macht es zu einem unpraktische Wahl in Umgebungen, in denen Vorhersagen schnell getroffen werden müssen. Darüber hinaus gibt es schnellere Algorithmen, die genauere Klassifizierungs- und Regressionsergebnisse liefern können.
Vorausgesetzt, Sie verfügen über ausreichende Rechenressourcen, um die Daten, mit denen Sie Vorhersagen treffen, schnell zu verarbeiten, kann KNN dennoch bei der Lösung hilfreich sein Probleme mit Lösungen, die von der Identifizierung ähnlicher Objekte abhängen. Ein Beispiel hierfür ist die Verwendung des KNN-Algorithmus in Empfehlungssystemen, einer Anwendung der KNN-Suche.
Empfehlungssysteme
Im Maßstab würde dies so aussehen, als würden Produkte bei Amazon empfohlen, Artikel auf Medium, Filme auf Netflix oder Videos auf YouTube. Wir können jedoch sicher sein, dass alle aufgrund des enormen Datenvolumens, das sie verarbeiten, effizientere Mittel zur Abgabe von Empfehlungen verwenden.
Wir könnten jedoch eines dieser Empfehlungssysteme in kleinerem Maßstab mit dem, was wir haben, replizieren hier in diesem Artikel gelernt. Lassen Sie uns den Kern eines Filmempfehlungssystems aufbauen.
Welche Frage versuchen wir zu beantworten?
Welche 5 Filme sind angesichts einer Filmabfrage einer Filmabfrage am ähnlichsten?
Sammeln Sie Filmdaten
Wenn wir bei Netflix, Hulu oder IMDb arbeiten würden, könnten wir die Daten aus ihrem Data Warehouse abrufen. Da wir in keinem dieser Unternehmen arbeiten, müssen wir unsere Daten auf andere Weise abrufen. Wir könnten einige Filmdaten aus dem UCI Machine Learning Repository, dem IMDb-Datensatz, verwenden oder sorgfältig unsere eigenen erstellen.
Erforschen, bereinigen und vorbereiten Sie die Daten
Wo immer wir unsere Daten erhalten haben Es kann sein, dass einige Dinge falsch sind, die wir korrigieren müssen, um es für den KNN-Algorithmus vorzubereiten. Beispielsweise haben die Daten möglicherweise nicht das Format, das der Algorithmus erwartet, oder es fehlen Werte, die wir füllen oder aus den Daten entfernen sollten, bevor wir sie in den Algorithmus weiterleiten.
Unsere obige KNN-Implementierung basiert darauf auf strukturierten Daten. Es muss in einem Tabellenformat vorliegen. Darüber hinaus geht die Implementierung davon aus, dass alle Spalten numerische Daten enthalten und dass die letzte Spalte unserer Daten Beschriftungen enthält, für die wir einige Funktionen ausführen können. Wo immer wir unsere Daten her haben, müssen wir sie diesen Einschränkungen anpassen.
Die folgenden Daten sind ein Beispiel dafür, wie unsere bereinigten Daten aussehen könnten. Die Daten enthalten 30 Filme, einschließlich Daten für jeden Film in sieben Genres und deren IMDB-Bewertungen. Die Beschriftungsspalte enthält alle Nullen, da wir diesen Datensatz nicht zur Klassifizierung oder Regression verwenden.
Außerdem gibt es Beziehungen zwischen den Filmen, die nicht berücksichtigt werden (z. B. Schauspieler, Regisseure und Themen) bei Verwendung des KNN-Algorithmus, einfach weil die Daten, die diese Beziehungen erfassen, im Datensatz fehlen. Wenn wir den KNN-Algorithmus für unsere Daten ausführen, basiert die Ähnlichkeit daher ausschließlich auf den enthaltenen Genres und den IMDB-Bewertungen der Filme.
Verwenden Sie den Algorithmus
Stellen Sie sich einen Moment vor . Wir navigieren auf der MoviesXb-Website, einem fiktiven IMDb-Spin-off, und begegnen The Post. Wir sind uns nicht sicher, ob wir es sehen wollen, aber seine Genres faszinieren uns. Wir sind neugierig auf andere ähnliche Filme. Wir scrollen nach unten zum Abschnitt „Mehr davon“, um zu sehen, welche Empfehlungen MoviesXb geben wird, und die algorithmischen Gänge beginnen sich zu drehen.
Die MoviesXb-Website sendet eine Anfrage an das Back-End für die 5 Filme, die sind The Post am ähnlichsten. Das Back-End verfügt über einen Empfehlungsdatensatz, der genau unserem entspricht. Zunächst wird die Zeilendarstellung (besser bekannt als Feature-Vektor) für The Post erstellt und anschließend ein Programm ausgeführt, das dem folgenden ähnelt Suchen Sie nach den 5 Filmen, die The Post am ähnlichsten sind, und senden Sie die Ergebnisse schließlich an die MoviesXb-Website zurück.
Wenn wir dieses Programm ausführen, sehen wir, dass MoviesXb 12 Jahre Sklave, Hacksaw Ridge, Königin von Katwe, The Wind Rises und A Beautiful Mind empfiehlt Nachdem wir nun vollständig verstanden haben, wie der KNN-Algorithmus funktioniert, können wir genau erklären, wie der KNN-Algorithmus zu diesen Empfehlungen gekommen ist. Herzlichen Glückwunsch!
Zusammenfassung
Das k-nahe Der KNN-Algorithmus (est neighbours) ist ein einfacher, überwachter Algorithmus für maschinelles Lernen, mit dem sowohl Klassifizierungs- als auch Regressionsprobleme gelöst werden können. Es ist einfach zu implementieren und zu verstehen, hat jedoch den großen Nachteil, dass es mit zunehmender Größe der verwendeten Daten erheblich langsamer wird.
KNN ermittelt die Abstände zwischen einer Abfrage und allen Beispielen in den Daten. Wählen Sie die angegebenen Zahlenbeispiele (K) aus, die der Abfrage am nächsten liegen, und wählen Sie dann die häufigste Bezeichnung (im Fall der Klassifizierung) oder mitteln Sie die Bezeichnungen (im Fall der Regression).
Im Fall von Bei der Klassifizierung und Regression haben wir festgestellt, dass die Auswahl des richtigen K für unsere Daten durch Ausprobieren mehrerer Ks und Auswahl des am besten funktionierenden K erfolgt.
Schließlich haben wir uns ein Beispiel für die Verwendung des KNN-Algorithmus angesehen in Empfehlungssystemen eine Anwendung der KNN-Suche.