Diagrammdurchquerungen
Diagrammdurchquerung bedeutet, jeden Scheitelpunkt und jede Kante genau einmal in einem Bohrloch zu besuchen -definierte Reihenfolge. Bei der Verwendung bestimmter Diagrammalgorithmen müssen Sie sicherstellen, dass jeder Scheitelpunkt des Diagramms genau einmal besucht wird. Die Reihenfolge, in der die Scheitelpunkte besucht werden, ist wichtig und kann von dem Algorithmus oder der Frage abhängen, die Sie lösen.
Während einer Durchquerung ist es wichtig, dass Sie verfolgen, welche Scheitelpunkte besucht wurden. Die gebräuchlichste Methode zum Verfolgen von Scheitelpunkten besteht darin, sie zu markieren.
Breitensuche (BFS)
Es gibt viele Möglichkeiten, Diagramme zu durchlaufen. BFS ist der am häufigsten verwendete Ansatz.
BFS ist ein Durchlaufalgorithmus, bei dem Sie von einem ausgewählten Knoten (Quelle oder Startknoten) aus durchlaufen und den Graphen schichtweise durchlaufen sollten, um die Nachbarknoten (Knoten, die direkt mit dem Quellknoten verbunden sind) zu erkunden. Sie müssen sich dann zu den Nachbarknoten der nächsten Ebene bewegen.
Wie der Name BFS andeutet, müssen Sie den Graphen wie folgt in der Breite durchlaufen:
- Bewegen Sie sich zuerst horizontal und Besuchen Sie alle Knoten der aktuellen Ebene.
- Wechseln Sie zur nächsten Ebene.
Betrachten Sie das folgende Diagramm. 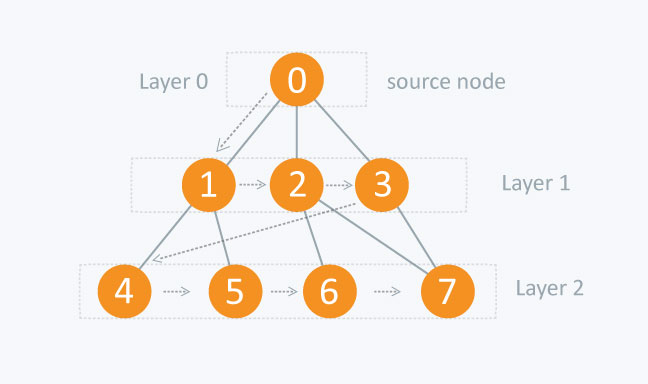
Der Abstand zwischen den Knoten in Schicht 1 ist vergleichsweise geringer als der Abstand zwischen den Knoten in Schicht 2. Daher müssen Sie in BFS alle Knoten in Schicht 1 durchlaufen, bevor Sie zu den Knoten in Schicht 2 wechseln.
Durchlaufen von untergeordneten Knoten
Ein Diagramm kann Zyklen enthalten, die Sie beim Durchlaufen des Diagramms möglicherweise wieder zum selben Knoten bringen. Verwenden Sie ein boolesches Array, das den Knoten nach seiner Verarbeitung markiert, um zu vermeiden, dass derselbe Knoten erneut verarbeitet wird. Speichern Sie die Knoten in der Ebene eines Diagramms so, dass Sie die entsprechenden untergeordneten Knoten in einer ähnlichen Reihenfolge durchlaufen können.
Um diesen Vorgang zu vereinfachen, speichern Sie den Knoten in einer Warteschlange und markieren Sie ihn als „besucht“, bis alle Nachbarn (Scheitelpunkte, die direkt mit ihm verbunden sind) markiert sind. Die Warteschlange folgt der FIFO-Warteschlangenmethode (First In First Out), und daher werden die Nachbarn des Knotens in der Reihenfolge besucht, in der sie in den Knoten eingefügt wurden, dh der zuerst eingefügte Knoten wird zuerst besucht, und so weiter auf.
Pseudocode
Verfahrvorgang 
Das Verfahren startet vom Quellknoten und schiebt s in die Warteschlange. s wird als „besucht“ markiert.
Erste Iteration
- s werden aus der Warteschlange entfernt.
- Nachbarn von s, dh 1 und 2, werden durchlaufen
- 1 und 2, die zuvor nicht durchlaufen wurden, werden durchlaufen. Dies sind:
- In die Warteschlange gestellt
- 1 und 2 werden als besucht markiert.
Zweite Iteration
- 1 wird aus der Warteschlange entfernt.
- Nachbarn von 1, dh s und 3 werden durchlaufen.
- s wird ignoriert, da sie als „besucht“ markiert ist.
- 3, das zuvor nicht durchlaufen wurde, wird durchlaufen. Es ist:
- In die Warteschlange verschoben
- Als besucht markiert
Dritte Iteration
- 2 wird aus der Warteschlange entfernt
- Nachbarn von 2, dh s, 3 und 4, werden durchlaufen
- 3 und s werden ignoriert, da sie als „besucht“
- 4, das zuvor nicht durchlaufen wurde, wird durchlaufen. Es ist:
- In die Warteschlange gestellt
- Als besucht markiert
- 4, das zuvor nicht durchlaufen wurde, wird durchlaufen. Es ist:
Vierte Iteration
- 3 wird aus der Warteschlange entfernt.
- Nachbarn von 3, dh 1, 2 und 5, werden durchlaufen.
- 1 und 2 werden ignoriert, da sie als „besucht“
- 5, das zuvor nicht durchlaufen wurde, wird durchlaufen. Es ist:
- In die Warteschlange verschoben
- Als besucht markiert
- 5, das zuvor nicht durchlaufen wurde, wird durchlaufen. Es ist:
Fünfte Iteration
- 4 wird aus der Warteschlange entfernt.
- Nachbarn von 4, dh 2 wird durchlaufen.
- 2 wird ignoriert, da es bereits als „besucht“ markiert ist.
Sechste Iteration
- 5 wird aus der Warteschlange entfernt
- Nachbarn von 5, dh 3 wird durchlaufen
- 3 wird ignoriert, weil dies der Fall ist bereits als „besucht“ markiert
Die Warteschlange ist leer und kommt aus der Schleife heraus. Alle Knoten wurden mit BFS durchlaufen.
Wenn alle Kanten in einem Diagramm das gleiche Gewicht haben, kann BFS auch verwendet werden, um den Mindestabstand zwischen den Knoten in einem Diagramm zu ermitteln.
Beispiel
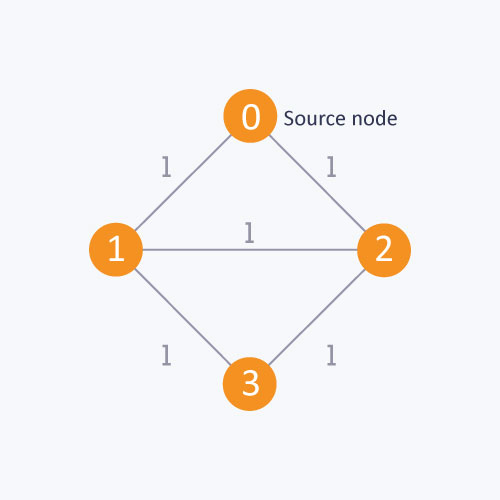
Beginnen Sie wie in diesem Diagramm am Quellknoten, um den Abstand zwischen den Quellen zu ermitteln Knoten und Knoten 1. Wenn Sie dem BFS-Algorithmus nicht folgen, können Sie vom Quellknoten zum Knoten 2 und dann zum Knoten 1 wechseln. Bei diesem Ansatz wird der Abstand zwischen dem Quellknoten und dem Knoten 1 als 2 berechnet, während das Minimum Die Entfernung beträgt tatsächlich 1. Die Mindestentfernung kann mithilfe des BFS-Algorithmus korrekt berechnet werden.
Komplexität
Die zeitliche Komplexität von BFS ist O (V + E), wobei V die Anzahl der Knoten und E die Anzahl der Kanten ist.
Anwendungen
1. Wie bestimme ich die Ebene jedes Knotens im angegebenen Baum?
Wie Sie in BFS wissen, durchlaufen Sie die Ebene weise. Sie können auch BFS verwenden, um die Ebene jedes Knotens zu bestimmen.
Implementierung
Dieser Code ähnelt dem BFS-Code mit nur dem folgenden Unterschied:
level] = level + 1;
In diesem Code wird beim Besuch jedes Knotens die Ebene dieses Knotens mit einem Inkrement in der Ebene seines übergeordneten Knotens festgelegt. Auf diese Weise wird die Ebene jedes Knotens bestimmt.
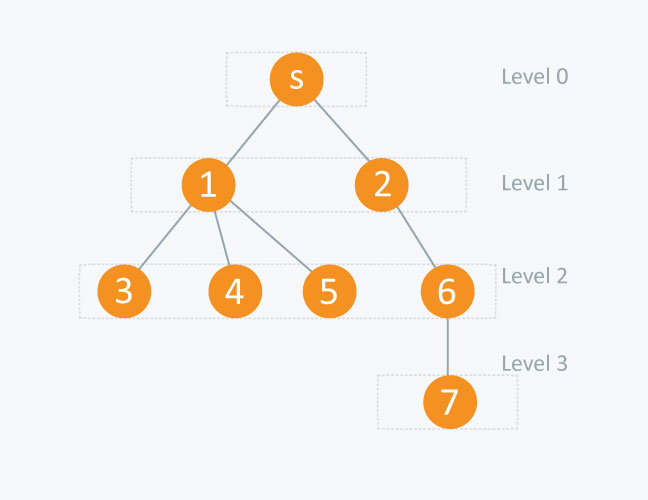
2 . 0-1 BFS
Diese Art von BFS wird verwendet, um den kürzesten Abstand zwischen zwei Knoten in einem Diagramm zu ermitteln, vorausgesetzt, die Kanten im Diagramm haben die Gewichte 0 oder 1. Wenn Sie das zuvor erläuterte BFS anwenden In diesem Artikel erhalten Sie ein falsches Ergebnis für den optimalen Abstand zwischen zwei Knoten.
Bei diesem Ansatz wird kein boolesches Array zum Markieren des Knotens verwendet, da der Zustand des optimalen Abstands bei Ihnen überprüft wird Besuchen Sie jeden Knoten. Eine Warteschlange mit zwei Enden wird zum Speichern des Knotens verwendet. Wenn in 0-1 BFS das Gewicht der Kante = 0 ist, wird der Knoten an die Vorderseite der Warteschlange geschoben. Wenn das Gewicht der Kante = 1 ist, wird der Knoten auf die Rückseite der Warteschlange geschoben.
Implementierung
Q ist eine Warteschlange mit zwei Enden. Die Entfernung ist ein Array, in dem die Entfernung die Entfernung vom Startknoten zum v-Knoten enthält. Anfänglich ist der vom Quellknoten zu jedem Knoten definierte Abstand unendlich.
Lassen Sie uns diesen Code anhand des folgenden Diagramms verstehen:
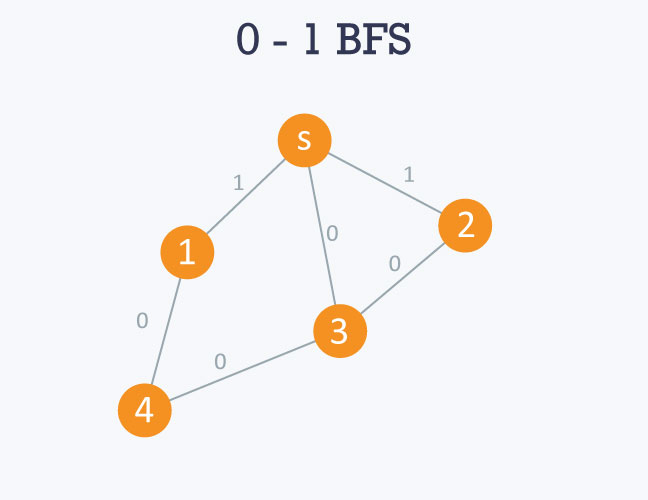
Die Adjazenzliste des Diagramms lautet wie folgt:
Hier wird „s“ als 0 oder Quellknoten betrachtet.
0 – > 1 – > 3 – > 2
Kanten.Erste = 1, Kanten.Sekunde = 1
Kanten.Erste = 3, Kanten.Sekunde = 0
Kanten.Erste = 2, Kanten.Sekunde = 1
1 – > 0 – > 4
Kanten.Erste = 0, Kanten.Sekunde = 1
Kanten.Erste = 4 , edge.second = 0
2 – > 0 – > 3
edge.first = 0 , Kanten.Sekunde = 0
Kanten.Erste = 3, Kanten.Sekunde = 0
3 – > 0 – > 2 – > 4
Kanten.Erste = 0, Kanten.Sekunde = 0
Kanten.Erste = 2, Kanten.Sekunde = 0
Kanten.Erste = 4, Kanten.Sekunde = 0
4 – > 1 – > 3
Kanten.Erste = 1, Kanten.Sekunde = 0
Kanten.Erste = 3, Kanten.Sekunde = 0
Wenn Sie den BFS-Algorithmus verwenden, ist das Ergebnis falsch, da es Sie anzeigt der optimale Abstand zwischen s und Knoten 1 und s bzw. Knoten 2 als 1. Dies liegt daran, dass es die Kinder von s besucht und den Abstand zwischen s und seinen Kindern berechnet, der 1 ist. Der tatsächliche optimale Abstand beträgt in beiden Fällen 0.
Verarbeitung
Ausgehend vom Quellknoten, dh 0, bewegt er sich in Richtung 1, 2 und 3. Da das Kantengewicht zwischen 0 und 1 und 0 bzw. 2 1 beträgt , 1 und 2 werden in den hinteren Bereich der Warteschlange verschoben. Da jedoch das Kantengewicht zwischen 0 und 3 0 ist, wird 3 an die Spitze der Warteschlange verschoben. Die Entfernung wird entsprechend im Entfernungsarray beibehalten.
3 wird dann aus der Warteschlange entfernt und der gleiche Prozess wird auf die Nachbarn usw. angewendet.