Vi så, at det er muligt at bruge forskellige formede funktioner (kurver) til at modellere data. At vælge hvilken kurve, der skal bruges (lineær, kvadratisk, eksponentiel) var let, så længe spredningsdiagrammet viste en lighed med den aktuelle kurve. Men hvad hvis det er uklart, hvilken kurve der skal vælges?
(lineær versus ikke-lineær)
En rest er forskellen mellem, hvad der er plottet i dit spredningsdiagram på et bestemt punkt, og hvad regressionsligningen forudsiger “skal afbildes” på dette specifikke punkt. Hvis spredningsdiagrammet og regressionsligningen “er enige” om en y-værdi (ingen forskel), vil den resterende være nul.
|
||||
Lineære foreninger er de mest populære statistiske forhold, da de er lette at læse og fortolke. Vi bruger størstedelen af vores tid på at arbejde med lineære forhold, og rester kan fortælle os, hvornår vi har en passende lineær model.
Når du ser på dit spredningsdiagram, og du er usikker på, om den form (kurve) du valgte til din regressionsligning skaber den bedste model, et restplot hjælper dig med at træffe en beslutning om, hvorvidt den valgte model vil være eller ikke vil være en passende lineær model.
Passende lineær model: når plot placeres tilfældigt, over og under x-aksen (y = 0).
Passende ikke-lineær model: når plotter følger et mønster, der ligner en kurve.
|
Du bliver bedt om at finde en ligning for at modellere dataene i sættet {(1,2), (2,1), (3,3½), (4,3), (5,4½)}. Du forbereder en spred plot for at se, om du skulle være på udkig efter en lineær, kvadratisk eller eksponentiel regressionsligning. Du beslutter dig for at vælge en lineær regression, men du er ikke 100% sikker på dit valg. Du bruger din grafregner til at finde den lineære regressionsligning, som er y = 0,7x + 0,7. Du tegner linjen for regressionsligningen på spredningsdiagrammet som vist nedenfor. |
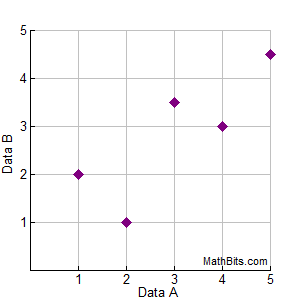 |
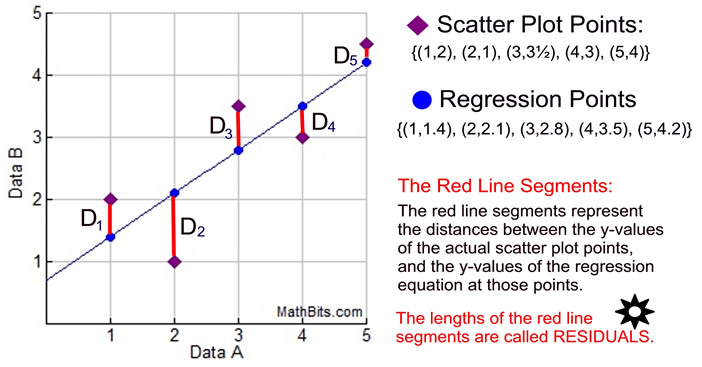
|

![]()
Restprodukter var grundlaget for den statistisk aftalte definition
af en “bedste tilpasningslinje (eller kurve) “.
D12 + D22 + … + Dn2 vil være et minimum.
En kurve med denne egenskab, hvor kvadratet af de lodrette afstande fra datapunkterne til kurven er så lille som muligt , kaldes en mindste kvadratkurve.
Regressionslinje med mindste firkanter = Regressionslinie af “Bedste” pasform
![]()
Restprodukter på grafregnemaskinen:
|
Når regressionsmodeller er beregnet på den grafiske lommeregner, gemmes rester automatisk i en liste kaldet RESID. Følg nedenstående links for at se, hvordan du arbejder med rester på din lommeregner.
|
|||||||
|
|
||||||
