KN-nærmeste naboer (KNN) algoritme er en enkel, nem at implementere overvåget maskinindlæringsalgoritme, der kan bruges til at løse begge klassifikationer og regression problemer. Pause! Lad os pakke det ud.

En overvåget maskinlæringsalgoritme (i modsætning til en ikke-overvåget maskinindlæringsalgoritme) er en, der er afhængig af mærket inputdata til lære en funktion, der producerer en passende output, når der gives nye umærkede data.
Forestil dig, at en computer er et barn, vi er dets tilsynsførende (f.eks. forælder, værge eller lærer), og vi vil have barnet (computeren) for at lære, hvordan en gris ser ud. Vi viser barnet flere forskellige billeder, hvoraf nogle er grise, og resten kan være billeder af alt (katte, hunde osv.).
Når vi ser en gris, råber vi “gris!” Når det ikke er en gris, råber vi “nej, ikke gris!” Efter at have gjort dette flere gange med barnet viser vi dem et billede og spørger “gris?” og de vil korrekt (det meste af tiden) sige “gris!” eller “nej, ikke gris!” afhængigt af hvad billedet er. Det er maskinlæring, der overvåges.

Overvågede maskinlæringsalgoritmer bruges til at løse klassificerings- eller regressionsproblemer.
Et klassificeringsproblem har en diskret værdi som output. For eksempel er “kan lide ananas på pizza” og “kan ikke lide ananas på pizza” diskrete. Der er ingen mellemvej. Ovenstående analogi med at lære et barn at identificere en gris er et andet eksempel på et klassificeringsproblem.

Dette billede viser et grundlæggende eksempel på, hvordan klassificeringsdata kan se ud. Vi har en forudsigelse (eller et sæt forudsigere) og en etiket. På billedet forsøger vi muligvis at forudsige, om nogen kan lide ananas (1) på deres pizza eller ej (0) baseret på deres alder (forudsigeren).
Det er almindelig praksis at repræsentere output ( etiket) af en klassificeringsalgoritme som et heltal, såsom 1, -1 eller 0. I dette tilfælde er disse tal rent repræsentative. Matematiske operationer bør ikke udføres på dem, fordi det ville være meningsløst. Tænk et øjeblik. Hvad er “kan lide ananas” + “kan ikke lide ananas”? Nemlig. Vi kan ikke tilføje dem, så vi bør ikke tilføje deres numeriske repræsentationer.
Et regressionsproblem har et reelt tal (et tal med et decimaltegn) som output. For eksempel kunne vi bruge dataene i nedenstående tabel til at estimere en persons vægt i forhold til deres højde.
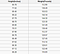
Data, der bruges i en regressionsanalyse, vil ligne de data, der er vist i billedet ovenfor. Vi har en uafhængig variabel (eller et sæt uafhængige variabler) og en afhængig variabel (det, vi prøver at gætte på grund af vores uafhængige variabler). For eksempel kan vi sige, at højden er den uafhængige variabel, og vægten er den afhængige variabel.
Hver række kaldes også typisk et eksempel, observation eller datapunkt, mens hver kolonne (ikke inklusive etiketten / afhængig variabel) kaldes ofte en forudsiger, dimension, uafhængig variabel eller funktion.
En ikke-overvåget algoritme til maskinindlæring bruger inputdata uden nogen etiketter – med andre ord, ingen lærer (etiket), der fortæller barnet (computer) når det er rigtigt, eller når det har lavet en fejl, så det kan korrigere sig selv.
I modsætning til overvåget læring, der forsøger at lære en funktion, der giver os mulighed for at forudsige givet nogle nye umærkede data , ikke-overvåget læring forsøger at lære den grundlæggende struktur af dataene for at give os mere indsigt i dataene.
K-tætteste naboer
KNN-algoritmen antager, at lignende ting findes i nærheden . Med andre ord er lignende ting tæt på hinanden.
“En fjerfugl strømmer sammen.”

Bemærk på billedet ovenfor, at lignende datapunkter for det meste er tæt på hinanden. KNN-algoritmen afhænger af, at denne antagelse er sand nok til, at algoritmen kan være nyttig. KNN fanger ideen om lighed (undertiden kaldet afstand, nærhed eller nærhed) med nogle matematik, vi måske har lært i vores barndom – beregner afstanden mellem punkter i en graf.
Bemærk: En forståelse af, hvordan vi beregne afstanden mellem punkterne på en graf er nødvendig, før du går videre. Hvis du ikke er bekendt med eller har brug for en opdatering af, hvordan denne beregning udføres, skal du læse “Distance Between 2 Points” i sin helhed og komme lige tilbage.
Der er andre måder at beregne afstanden på, og en måde kunne være at foretrække afhængigt af det problem, vi løser. Den lige afstand (også kaldet euklidisk afstand) er imidlertid et populært og velkendt valg.
KNN-algoritmen
- Indlæs dataene
- Initialiser K til dit valgte antal naboer
3. For hvert eksempel i dataene
3.1 Beregn afstand mellem forespørgseleksemplet og det aktuelle eksempel fra dataene.
3.2 Føj afstanden og indekset for eksemplet til en ordnet samling
4. Sorter den ordnede samling af afstande og indekser fra mindste til største (i stigende rækkefølge) efter afstandene
5. Vælg de første K-poster fra den sorterede samling
6. Få etiketterne for de valgte K-poster
7. Hvis regression, ret urn gennemsnittet af K-etiketterne
8. Hvis klassificering skal returneres tilstanden for K-etiketterne
KNN-implementeringen (fra bunden)
Valg af den rigtige værdi til K
For at vælge den K, der passer til dine data, kører vi KNN-algoritmen flere gange med forskellige K-værdier og vælg K, der reducerer antallet af fejl, vi støder på, samtidig med at algoritmens evne til nøjagtigt at forudsige forudsigelser når den får data, den ikke har set før.
Her er nogle ting at holde i mind:
- Når vi reducerer værdien af K til 1, bliver vores forudsigelser mindre stabile. Tænk et øjeblik, forestil dig K = 1, og vi har et forespørgselspunkt omgivet af flere røde og en grøn (jeg tænker på det øverste venstre hjørne af det farvede plot ovenfor), men det grønne er den nærmeste nabo. Vi ville med rimelighed tro, at forespørgselspunktet sandsynligvis er rødt, men fordi K = 1 forudsiger KNN forkert, at forespørgselspunktet er grønt.
- Omvendt, når vi øger værdien af K, bliver vores forudsigelser mere stabil på grund af flertalsafstemning / gennemsnit, og dermed mere sandsynligt at give mere nøjagtige forudsigelser (op til et bestemt punkt). Til sidst begynder vi at være vidne til et stigende antal fejl. Det er på dette tidspunkt, at vi ved, at vi har skubbet værdien af K for langt.
- I de tilfælde, hvor vi tager flertalsafstemning (f.eks. Vælger tilstanden i et klassificeringsproblem) blandt etiketter, laver vi normalt K et ulige tal for at have en tiebreaker.
Fordele
- Algoritmen er enkel og nem at implementere.
- Der er ikke behov for opbyg en model, indstil flere parametre, eller lav yderligere antagelser.
- Algoritmen er alsidig. Det kan bruges til klassificering, regression og søgning (som vi vil se i næste afsnit).
Ulemper
- Algoritmen bliver betydeligt langsommere, efterhånden som antallet af eksempler og / eller forudsigere / uafhængige variabler stiger.
KNN i praksis
KNNs største ulempe ved at blive betydeligt langsommere, når datamængden stiger, gør det til et upraktisk valg i miljøer, hvor forudsigelser skal foretages hurtigt. Der er desuden hurtigere algoritmer, der kan producere mere nøjagtige klassificerings- og regressionsresultater.
Men forudsat at du har tilstrækkelige computervinduer til hurtigt at håndtere de data, du bruger til at forudsige, kan KNN stadig være nyttig til at løse problemer, der har løsninger, der afhænger af identifikation af lignende objekter. Et eksempel på dette er at bruge KNN-algoritmen i anbefalingssystemer, en anvendelse af KNN-søgning.
Anbefalersystemer
I skala ser det ud som at anbefale produkter på Amazon, artikler om Medium, film på Netflix eller videoer på YouTube. Selvom vi kan være sikre på, at de alle bruger mere effektive metoder til at komme med anbefalinger på grund af den enorme mængde data, de behandler.
Vi kunne dog replikere et af disse anbefalingssystemer i mindre skala ved hjælp af det, vi har lært her i denne artikel. Lad os bygge kernen i et filmanbefalingssystem.
Hvilket spørgsmål prøver vi at besvare?
I betragtning af vores datasæt til film, hvad er de 5 mest ens film til en filmforespørgsel?
Saml filmdata
Hvis vi arbejdede hos Netflix, Hulu eller IMDb, kunne vi hente dataene fra deres datalager. Da vi ikke arbejder hos nogen af disse virksomheder, er vi nødt til at hente vores data på andre måder. Vi kunne bruge nogle filmdata fra UCI Machine Learning Repository, IMDbs datasæt eller omhyggeligt oprette vores egne.
Udforsk, rens og forbered dataene
Uanset hvor vi har fået vores data , der kan være nogle ting galt med det, som vi skal rette for at forberede det til KNN-algoritmen. For eksempel er data muligvis ikke i det format, som algoritmen forventer, eller der kan være manglende værdier, som vi skal udfylde eller fjerne fra dataene, før vi sender dem til algoritmen.
Vores KNN-implementering ovenfor er afhængig af på strukturerede data. Det skal være i et tabelformat. Derudover forudsætter implementeringen, at alle kolonner indeholder numeriske data, og at den sidste kolonne i vores data har etiketter, som vi kan udføre en funktion på. Så uanset hvor vi har vores data fra, er vi nødt til at gøre dem i overensstemmelse med disse begrænsninger.
Dataene nedenfor er et eksempel på, hvad vores rensede data kan ligne. Dataene indeholder tredive film, inklusive data for hver film på tværs af syv genrer og deres IMDB-ratings. Etiketterkolonnen har alle nuller, fordi vi ikke bruger dette datasæt til klassificering eller regression.
Der er desuden forhold mellem filmene, der ikke tages højde for (f.eks. skuespillere, instruktører og temaer) når du bruger KNN-algoritmen, simpelthen fordi de data, der registrerer disse forhold, mangler i datasættet. Derfor, når vi kører KNN-algoritmen på vores data, vil ligheden kun være baseret på de inkluderede genrer og IMDB-klassificeringerne af filmene.
Brug algoritmen
Forestil dig et øjeblik . Vi navigerer på MoviesXb-webstedet, en fiktiv IMDb-spin-off, og vi støder på The Post. Vi er ikke sikre på, at vi vil se det, men dets genrer fascinerer os; vi er nysgerrige efter andre lignende film. Vi ruller ned til sektionen “Mere som dette” for at se, hvilke anbefalinger MoviesXb vil komme med, og de algoritmiske gear begynder at dreje.
MoviesXb-webstedet sender en anmodning til sin back-end for de 5 film, som ligner mest The Post. Back-enden har et anbefalet datasæt nøjagtigt som vores. Det begynder med at oprette rækkerepræsentationen (bedre kendt som en funktionsvektor) for The Post, så kører det et program svarende til det nedenfor for at søg efter de 5 film, der ligner mest The Post, og send til sidst resultaterne tilbage til MoviesXb-webstedet.
Når vi kører dette program, ser vi, at MoviesXb anbefaler 12 Years A Slave, Hacksaw Ridge, Queen of Katwe, The Wind Rises og A Beautiful Mind Nu hvor vi fuldt ud forstår, hvordan KNN-algoritmen fungerer, er vi i stand til nøjagtigt at forklare, hvordan KNN-algoritmen kom til at komme med disse anbefalinger. Tillykke!
Oversigt
K-near est neighbours (KNN) algoritme er en enkel, overvåget algoritme til maskinindlæring, der kan bruges til at løse både klassificerings- og regressionsproblemer. Det er let at implementere og forstå, men har en stor ulempe ved at blive betydeligt langsommere, når størrelsen på de anvendte data vokser.
KNN arbejder ved at finde afstandene mellem en forespørgsel og alle eksemplerne i dataene, at vælge de angivne antal eksempler (K) tættest på forespørgslen og derefter stemme på den hyppigste etiket (i tilfælde af klassificering) eller gennemsnitlig etiketter (i tilfælde af regression).
I tilfælde af klassificering og regression, så vi, at valg af den rigtige K til vores data sker ved at prøve flere Ker og vælge den, der fungerer bedst.
Endelig så vi på et eksempel på, hvordan KNN-algoritmen kunne bruges i anbefalingssystemer, en anvendelse af KNN-søgning.