Algoritmus k-nejbližší sousedé (KNN) je jednoduchý a snadno implementovatelný algoritmus strojového učení pod dohledem, který lze použít k řešení obou klasifikací a regresní problémy. Pauza! Rozbalme to.

Algoritmus strojového učení pod dohledem (na rozdíl od algoritmu strojového učení bez dozoru) je ten, který se spoléhá na označená vstupní data Naučte se funkci, která vytváří vhodný výstup, když dostanete nová neoznačená data.
Představte si, že počítač je dítě, jsme jeho nadřízený (např. rodič, opatrovník nebo učitel) a chceme dítě (počítač) naučit se, jak vypadá prase. Ukážeme dítěti několik různých obrázků, z nichž některá jsou prasata a zbytek mohou být obrázky čehokoli (kočky, psi atd.).
Když uvidíme prase, zakřičíme „prase“! Když to není prase, křičíme „ne, ne prase!“ Poté, co jsme to s dítětem udělali několikrát, ukážeme jim obrázek a zeptáme se „prase?“ a budou správně (většinou) říkat „prase!“ nebo „ne, ne prase!“ podle toho, jaký je obrázek. To je strojové učení pod dohledem.

K řešení problémů s klasifikací nebo regresí se používají supervizované algoritmy strojového učení.
Problém klasifikace má jako výstup diskrétní hodnotu. Například „má rád ananas na pizze“ a „nemá rád ananas na pizze“ je diskrétní. Neexistuje žádná střední cesta. Výše uvedená analogie s učením dítěte identifikovat prase je dalším příkladem klasifikačního problému.

Tento obrázek ukazuje základní příklad toho, jak mohou vypadat klasifikační údaje. Máme prediktor (nebo sadu prediktorů) a štítek. Na obrázku se možná pokoušíme předpovědět, zda má někdo na pizze rád ananas (1), nebo ne (0) na základě jeho věku (prediktor).
Je běžnou praxí reprezentovat výstup ( štítek) klasifikačního algoritmu jako celé číslo, například 1, -1 nebo 0. V tomto případě jsou tato čísla čistě reprezentativní. Matematické operace by se na nich neměly provádět, protože by to nemělo smysl. Přemýšlejte na chvíli. Co je „má rád ananas“ + „nemá rád ananas“? Přesně. Nemůžeme je přidat, takže bychom neměli přidávat jejich číselná vyjádření.
Regresní problém má jako výstup reálné číslo (číslo s desetinnou čárkou). Například můžeme použít údaje v tabulce níže k odhadu váhy někoho vzhledem k jeho výšce.
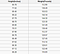
Data použitá při regresní analýze budou vypadat podobně jako data uvedená na obrázku výše. Máme nezávislou proměnnou (nebo sadu nezávislých proměnných) a závislou proměnnou (věc, kterou se snažíme uhodnout vzhledem k našim nezávislým proměnným). Například bychom mohli říci, že výška je nezávislá proměnná a váha je závislá proměnná.
Každý řádek se také obvykle nazývá příklad, pozorování nebo datový bod, zatímco každý sloupec (bez štítku / závislá proměnná) se často nazývá prediktor, dimenze, nezávislá proměnná nebo prvek.
Algoritmus strojového učení bez dozoru využívá vstupní data bez jakýchkoli štítků – jinými slovy, žádný učitel (štítek) neřekne dítěti (počítač), když má pravdu, nebo když udělala chybu, aby se mohla samočinně opravit.
Na rozdíl od supervizovaného učení, které se snaží naučit funkci, která nám umožní dělat předpovědi dané některými novými neoznačenými daty , bezobslužné učení se snaží naučit základní strukturu dat, aby nám poskytlo lepší přehled o datech.
K-Nearest Neighbors
Algoritmus KNN předpokládá, že podobné věci existují v těsné blízkosti . Jinými slovy, podobné věci jsou si navzájem blízké.
„Ptáci pírka se hrnou dohromady.“”

Na obrázku výše si všimněte, že podobné datové body jsou většinou blízko sebe. Algoritmus KNN závisí na tom, zda je tento předpoklad dostatečně pravdivý, aby byl algoritmus užitečný. KNN zachycuje myšlenku podobnosti (někdy nazývanou vzdálenost, blízkost nebo blízkost) s nějakou matematikou, kterou jsme se mohli naučit v dětství – výpočet vzdálenosti mezi body v grafu.
Poznámka: Porozumění tomu, jak vypočítat vzdálenost mezi body v grafu je nutné před pokračováním. Pokud nejste obeznámeni nebo potřebujete aktualizovat, jak se tento výpočet provádí, důkladně si přečtěte celý text „Vzdálenost mezi 2 body“ a vraťte se zpět.
Existují i jiné způsoby výpočtu vzdálenosti a jeden způsob může být výhodnější v závislosti na problému, který řešíme. Rovná vzdálenost (nazývaná také euklidovská vzdálenost) je oblíbenou a známou volbou.
Algoritmus KNN
- Načtěte data
- Inicializujte K na vámi zvolený počet sousedů
3. Pro každý příklad v datech
3.1 Vypočítejte vzdálenost mezi příkladem dotazu a aktuálním příkladem z dat.
3.2 Přidejte vzdálenost a index příkladu do uspořádané kolekce
4. Seřadit seřazenou kolekci vzdáleností a indexy od nejmenších po největší (ve vzestupném pořadí) podle vzdáleností
5. Vyberte první K položky z tříděné kolekce
6. Získejte popisky vybraných K položek
7. Je-li regrese, ret urn průměr štítků K
8. Pokud je klasifikace, vraťte režim štítků K.
Implementace KNN (od nuly)
Výběr správné hodnoty pro K
Chcete-li vybrat K, která je pro vaše data správná, spustíme několikrát algoritmus KNN s různé hodnoty K a zvolte K, které snižuje počet chyb, se kterými se setkáváme, při zachování schopnosti algoritmu přesně vytvářet předpovědi, když jsou mu dána data, která předtím neviděl.
Zde je několik věcí, které je třeba udržovat mysl:
- Snižováním hodnoty K na 1 se naše předpovědi stávají méně stabilními. Jen na chvíli přemýšlejte, představte si K = 1 a máme bod dotazu obklopený několika červenými a jedním zeleným (myslím na levý horní roh barevného grafu výše), ale zelená je jediný nejbližší soused. Rozumně bychom si mysleli, že bod dotazu je s největší pravděpodobností červený, ale protože K = 1, KNN nesprávně předpovídá, že bod dotazu je zelený.
- Naopak, jak zvyšujeme hodnotu K, naše předpovědi se stávají více stabilní díky většinovému hlasování / průměrování, a tedy s větší pravděpodobností dělat přesnější předpovědi (až do určitého bodu). Nakonec začneme být svědky rostoucího počtu chyb. V tuto chvíli víme, že jsme příliš posunuli hodnotu K.
- V případech, kdy vezmeme většinový hlas (např. Výběr režimu v klasifikačním problému) mezi štítky, obvykle uděláme K liché číslo, které má rozhodčího.
Výhody
- Algoritmus je jednoduchý a snadno implementovatelný.
- Není třeba vytvořit model, vyladit několik parametrů nebo vytvořit další předpoklady.
- Algoritmus je univerzální. Může být použit pro klasifikaci, regresi a vyhledávání (jak uvidíme v další části).
Nevýhody
- Algoritmus se výrazně zpomaluje, protože počet příkladů a / nebo prediktorů / nezávislých proměnných se zvyšuje.
KNN v praxi
Hlavní nevýhoda KNN spočívající v tom, že se výrazně zpomaluje s rostoucím objemem dat, což z něj dělá nepraktická volba v prostředích, kde je třeba rychle předpovídat. Kromě toho existují rychlejší algoritmy, které mohou produkovat přesnější výsledky klasifikace a regrese.
Pokud však máte dostatek výpočetních zdrojů pro rychlé zpracování dat, která používáte k vytváření předpovědí, může být KNN při řešení stále užitečný problémy, které mají řešení, které závisí na identifikaci podobných objektů. Příkladem toho je použití algoritmu KNN v doporučovacích systémech, aplikace vyhledávání KNN.
Doporučovací systémy
V měřítku by to vypadalo jako doporučení produktů na Amazonu, články o Médium, filmy na Netflixu nebo videa na YouTube. I když si můžeme být jisti, že všichni používají efektivnější způsoby vydávání doporučení kvůli enormnímu objemu dat, která zpracovávají.
Mohli bychom však jeden z těchto doporučovacích systémů replikovat v menším měřítku pomocí toho, co máme se dozvěděl zde v tomto článku. Postavme jádro systému doporučujícího filmy.
Na jakou otázku se snažíme odpovědět?
Vzhledem k naší datové sadě filmů, jaké jsou 5 nejpodobnějších filmů k dotazu na film?
Shromažďovat data filmů
Pokud bychom pracovali ve společnostech Netflix, Hulu nebo IMDb, mohli bychom získat data z jejich datového skladu. Vzhledem k tomu, že nepracujeme v žádné z těchto společností, musíme data získat nějakým jiným způsobem. Mohli bychom použít některá data filmů z úložiště strojového učení UCI, datové sady IMDb nebo pečlivě vytvořit vlastní.
Prozkoumejte, vyčistěte a připravte data
Kamkoli jsme naše data získali , mohou na něm být špatné věci, které musíme opravit, abychom je připravili na algoritmus KNN. Například data nemusí být ve formátu, který algoritmus očekává, nebo mohou chybět hodnoty, které bychom měli vyplňovat nebo odebírat z dat před jejich vložením do algoritmu.
Naše implementace KNN výše závisí na na strukturovaných datech. Musí být ve formátu tabulky. Implementace navíc předpokládá, že všechny sloupce obsahují číselná data a že poslední sloupec našich dat má štítky, na kterých můžeme provádět některé funkce. Takže odkudkoli jsme získali naše data, musíme je přizpůsobit těmto omezením.
Níže uvedená data jsou příkladem toho, jak by se naše vyčištěná data mohla podobat. Data obsahují třicet filmů, včetně dat pro každý film napříč sedmi žánry a jejich hodnocení IMDB. Sloupec štítky má všechny nuly, protože tuto datovou sadu nepoužíváme pro klasifikaci ani pro regresi.
Mezi filmy navíc existují vztahy, které nebudou brány v úvahu (např. herci, režiséři a témata) při použití algoritmu KNN jednoduše proto, že data, která zachycují tyto vztahy, v datové sadě chybí. Když tedy na našich datech spustíme algoritmus KNN, bude podobnost založena pouze na zahrnutých žánrech a hodnocení IMDB filmů.
Použijte algoritmus
Představte si na okamžik . Procházíme web MoviesXb, fiktivní spin-off IMDb, a setkáváme se s The Post. Nejsme si jisti, zda se na to chceme dívat, ale jeho žánry nás intrikují; jsme zvědaví na další podobné filmy. Posuneme se dolů do sekce „Více podobných“, abychom zjistili, jaká doporučení MoviesXb učiní, a algoritmické převody se začnou otáčet.
Web MoviesXb odešle požadavek na jeho back-end pro 5 filmů, které jsou nejvíce podobné příspěvku. V back-endu je sada dat doporučení přesně jako ta naše. Začíná to vytvořením řádkové reprezentace (lépe známé jako vektor funkcí) pro příspěvek, poté spustí program podobný následujícímu vyhledejte 5 filmů, které jsou nejvíce podobné filmu The Post, a nakonec odešlete výsledky zpět na web MoviesXb.
Když spustíme tento program, zjistíme, že MoviesXb doporučuje 12 Years A Slave, Hacksaw Ridge, Queen of Katwe, The Wind Rises a A Beautiful Mind . Nyní, když plně chápeme, jak funguje algoritmus KNN, jsme schopni přesně vysvětlit, jak algoritmus KNN přišel k provedení těchto doporučení. Gratulujeme!
Shrnutí
K-near Algoritmus est Neighbors (KNN) je jednoduchý algoritmus strojového učení pod dohledem, který lze použít k řešení klasifikačních i regresních problémů. Je snadné jej implementovat a pochopit, ale má hlavní nevýhodu v tom, že se významně zpomaluje s rostoucí velikostí používaných dat.
KNN funguje tak, že vyhledává vzdálenosti mezi dotazem a všemi příklady v datech, výběrem zadaného počtu příkladů (K) nejblíže k dotazu, pak hlasování pro nejčastější štítek (v případě klasifikace) nebo průměrování štítků (v případě regrese).
V případě klasifikace a regrese jsme zjistili, že výběr správného K pro naše data se provádí vyzkoušením několika K a výběrem toho, který funguje nejlépe.
Nakonec jsme se podívali na příklad, jak lze použít algoritmus KNN v systémech doporučujících aplikace KNN-search.