Toto je druhý v řadě článků o poddotazech. V tomto článku pojednáváme o poddotazech v seznamu sloupců příkazu SELECT. Další články pojednávají o jejich použití v jiných klauzulích.
Všechny příklady této lekce jsou založeny na Microsoft SQL Server Management Studio a databázi AdventureWorks2012. Tyto bezplatné nástroje můžete začít používat pomocí mé příručky Začínáme s používáním serveru SQL Server.
Použití poddotazů v příkazu Select
Když je poddotaz umístěn do seznamu sloupců, je zvyklý vrátit jednotlivé hodnoty. V tomto případě si poddotaz můžete představit jako jediný hodnotový výraz. Výsledek se neliší od výrazu „2 + 2.“ Samozřejmě, poddotazy mohou také vracet text, ale dostanete bod!
Při práci s poddotazy se hlavnímu příkazu někdy říká vnější dotaz. Poddotazy jsou uzavřeny v závorkách, což usnadňuje jejich vyhledání .
Při používání poddotazů buďte opatrní. Jejich použití může být zábavné, ale když do dotazu přidáte další, mohou váš dotaz zpomalit.
Jednoduchý poddotaz pro výpočet průměru
Začněme jednoduchým dotazem, který ukáže SalesOrderDetail a porovnáme jej s celkovým průměrem SalesOrderDetail LineTotal. Příkaz SELECT, který použijeme, je:
SELECT SalesOrderID,LineTotal,(SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail) AS AverageLineTotalFROM Sales.SalesOrderDetail;
Tento dotaz vrátí výsledky jako:
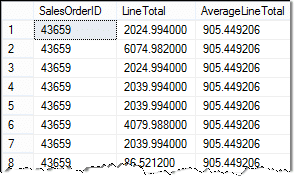
Poddotaz, který je zobrazen červeně výše, se spustí jako první k získání průměrného LineTotal.
SELECT AVG(LineTotal)FROM Sales.SalesOrderDetail
Tento výsledek se poté připojí zpět do seznamu sloupců a dotaz pokračuje. Chci poukázat na několik věcí :
- Poddotazy jsou uzavřeny v závorkách .
- Jsou-li v příkazu SELECT použity poddotazy, mohou vrátit pouze jednu hodnotu. To by mělo dávat smysl, jednoduše výběrem sloupce se vrací jedna hodnota pro řádek a musíme se řídit stejným vzorem.
- Obecně se poddotaz spustí pouze jednou pro celý dotaz a jeho výsledek se znovu použije . Důvodem je, že výsledek dotazu se u každého vráceného řádku neliší.
- Pro zlepšení čitelnosti je důležité používat aliasy pro názvy sloupců.
Jednoduchý poddotaz ve výrazu
Jak můžete očekávat, výsledek poddotazu lze použít v jiných výrazech. Na základě předchozího příkladu pojďme pomocí poddotazu určit, jak moc se náš LineTotal liší od průměru.
Odchylka je jednoduše LineTotal mínus průměrný součet. V následujícím poddotazu jsem jej vybarvil modře. Tady je vzorec pro odchylku:
LineTotal - (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail)
Poddotazem je příkaz SELECT uzavřený v závorkách. Stejně jako v předchozím příkladu se i tento dotaz spustí jednou, vrátí číselnou hodnotu, která se poté odečte od každé hodnoty LineTotal.
Zde je dotaz v konečné podobě:
SELECT SalesOrderID, LineTotal, (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail) AS AverageLineTotal, LineTotal - (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail) AS VarianceFROM Sales.SalesOrderDetail
Zde je výsledek:
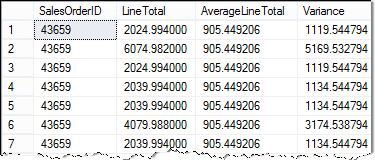
Při práci s poddotazy ve vybraných příkazech obvykle vytvářím a nejprve otestujte poddotaz. Příkazy SELECT se mohou velmi rychle zkomplikovat. Nejlepší je budovat je postupně. Budováním a testováním různých částí samostatně to opravdu pomáhá s laděním.
Korelované dotazy
Existují způsoby, jak začlenit hodnoty vnějšího dotazu do klauzulí poddotazu. Tyto typy dotazů se nazývají korelované poddotazy, protože výsledky z poddotazu jsou v nějaké formě připojeny k hodnotám ve vnějším dotazu. Korelovaným dotazům se někdy říká synchronizované dotazy.
Pokud máte potíže s tím, co znamená korelace, podívejte se na tuto definici od Googlu:
Korelace: „mít vzájemný vztah nebo spojení, ve kterém jedna věc ovlivňuje nebo na druhé závisí. “
Typickým použitím korelovaného poddotazu je jeden ze sloupců vnějšího dotazu v klauzuli WHERE vnitřního dotazu. To je v mnoha případech zdravý rozum omezit vnitřní dotaz na podmnožinu dat.
Příklad korelovaného poddotazu
Příklad korelovaného poddotazu poskytneme tak, že nahlásíme zpět každý SalesOrderDetail LineTotal a průměrný LineTotal pro celkový prodej Objednávka.
Tento požadavek se výrazně liší od našich dřívějších příkladů, protože průměr, který počítáme, se u každé prodejní objednávky liší.
Zde vstupují do hry korelované poddotazy. Můžeme použít hodnotu z vnějšího dotazu a začlenit ji do kritérií filtru poddotazu.
Vezměme si a podívejte se, jak vypočítáme průměrný součet řádků. K tomu jsem dal dohromady ilustraci, která ukazuje příkaz SELECT s poddotazem.
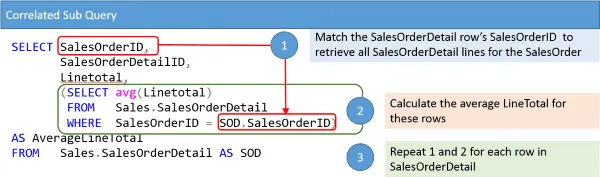
K dalšímu rozpracování diagram. Příkaz SELECT se skládá ze dvou částí, vnějšího dotazu a poddotazu. Vnější dotaz se používá k načtení všech řádků SalesOrderDetail.Poddotaz se používá k vyhledání a shrnutí řádků podrobností prodejní objednávky pro konkrétní SalesOrderID.
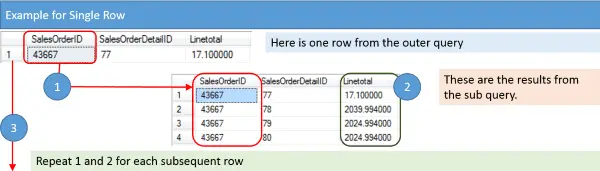
Pokud bych měl verbalizovat kroky vezmeme je, shrnul bych je takto:
- Získat SalesOrderID.
- Vrátit průměrný LineTotal ze všech položek SalesOrderDetail, kde se SalesOrderID shoduje.
- Pokračujte na další SalesOrderID ve vnějším dotazu a opakujte kroky 1 a 2.
Dotaz, který můžete spustit v databázi AdventureWork2012, je:
SELECT SalesOrderID, SalesOrderDetailID, LineTotal, (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail WHERE SalesOrderID = SOD.SalesOrderID) AS AverageLineTotalFROM Sales.SalesOrderDetail SOD
Zde jsou výsledky dotazu:
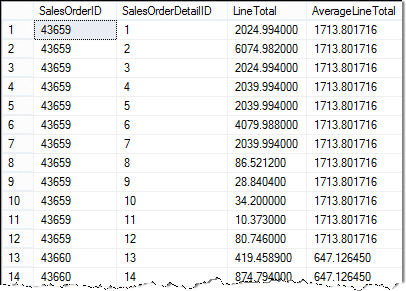
Existuje několik položky, na které je třeba poukázat.
- Můžete vidět, že jsem použil aliasy sloupců, které usnadňují čtení výsledků dotazu.
- Také jsem použil alias tabulky, SOD, pro vnější dotaz. Díky tomu je možné v poddotazu použít hodnoty vnějšího dotazu. Jinak dotaz nesouvisí!
- Pomocí aliasů tabulky je jednoznačné, které sloupce jsou z každé tabulky.
Rozdělení souvisejícího poddotazu
Zkusme to nyní rozdělit pomocí jazyka SQL.
Na začátek předpokládejme, že dostaneme náš příklad pro SalesOrderDetailID 20. Odpovídající SalesOrderID je 43661.
Získat průměrný LineTotal pro tuto položku je snadné
SELECT AVG(LineTotal)FROM Sales.SalesOrderDetailWHERE SalesOrderID = 43661
Tím se vrací hodnota 2181.765240.
Nyní, když máme průměr, můžeme zapojte jej do našeho dotazu
SELECT SalesOrderID, SalesOrderDetailID, LineTotal, 2181.765240 AS AverageLineTotalFROM Sales.SalesOrderDetailWHERE SalesOrderDetailID = 20
Pomocí poddotazů se to stane
SELECT SalesOrderID, SalesOrderDetailID, LineTotal, (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail WHERE SalesOrderID = 43661) AS AverageLineTotalFROM Sales.SalesOrderDetailWHERE SalesOrderDetailID = 20
Konečný dotaz je :
SELECT SalesOrderID, SalesOrderDetailID, LineTotal, (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetailWHERE SalesOrderID = SOD.SalesOrderID) AS AverageLineTotalFROM Sales.SalesOrderDetail AS SOD
Korelovaný poddotaz s jinou tabulkou
Korelovaný poddotaz, nebo dokonce jakýkoli poddotaz, může použít jinou tabulku než vnější dotaz. To se může hodit, když pracujete s „nadřazenou“ tabulkou, jako je SalesOrderHeader, a chcete do výsledku zahrnout souhrn podřízených řádků, jako jsou ty ze SalesOrderDetail.
Vraťme OrderDate, TotalDue a počet řádků podrobností prodejní objednávky. K tomu se můžeme orientovat pomocí následujícího diagramu:
Za tímto účelem do našeho příkazu SELECT zahrneme korelovaný poddotaz, který nám vrátí řádky COUNT z SalesOrderDetail. Zajistíme, že počítáme správnou položku SalesOrderDetail filtrováním na SalesOrderID vnějšího dotazu.
Zde je poslední příkaz SELECT:
SELECT SalesOrderID, OrderDate, TotalDue, (SELECT COUNT(SalesOrderDetailID) FROM Sales.SalesOrderDetail WHERE SalesOrderID = SO.SalesOrderID) as LineCountFROM Sales.SalesOrderHeader SO
Výsledky jsou:
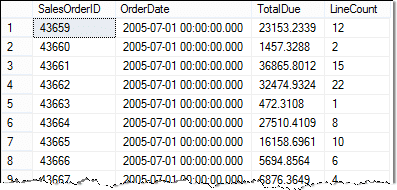
V tomto příkladu je třeba si všimnout těchto věcí:
- Poddotaz vybírá data z jiné tabulky než z vnějšího dotazu.
- Použil jsem tabulku a aliasy sloupců, aby bylo snazší číst SQL a výsledky.
- Nezapomeňte provést dvojitou kontrolu vaše klauzule kde! Pokud zapomenete zahrnout název tabulky nebo aliasy do klauzule WHERE poddotazu, dotaz nebude korelovat.
Korelované poddotazy versus vnitřní spojení
Je to důležité abyste pochopili, že stejných výsledků můžete dosáhnout pomocí poddotazu nebo spojení. Ačkoli oba vracejí stejné výsledky, každá metoda má výhody i nevýhody!
Zvažte poslední příklad, kde počítáme řádkové položky pro položky SalesHeader.
SELECT SalesOrderID, OrderDate, TotalDue, (SELECT COUNT(SalesOrderDetailID) FROM Sales.SalesOrderDetailWHERE SalesOrderID = SO.SalesOrderID) as LineCountFROM Sales.SalesOrderHeader SO
Stejný dotaz lze provést pomocí INNER JOIN spolu s GROUP BY as
SELECT SO.SalesOrderID, OrderDate, TotalDue, COUNT(SOD.SalesOrderDetailID) as LineCountFROM Sales.SalesOrderHeader SO INNER JOIN Sales.SalesOrderDetail SOD ON SOD.SalesOrderID = SO.SalesOrderIDGROUP BY SO.SalesOrderID, OrderDate, TotalDue
Který z nich je rychlejší?
Zjistíte, že mnoho lidí řekne, aby se vyhnuly poddotazům, protože jsou pomalejší. Budou tvrdit, že korelovaný poddotaz se musí „provést“ jednou pro každý řádek vrácený ve vnějším dotazu, zatímco INNER JOIN musí provést pouze jeden průchod dat.
Já sám? Sledoval jsem svůj vlastní plán pro oba výše uvedené příklady a zjistil jsem, že plány jsou stejné!
To neznamená, že by se plány změnily, kdyby bylo více dat, ale můj názor je, že byste neměli dělat jen předpoklady. Většina optimalizátorů SQL DBMS je opravdu dobrá v tom, jak zjistit nejlepší způsob, jak provést váš dotaz. Vezmou vaše syntaxe, jako je poddotaz, nebo INNER JOIN, a použijí je k vytvoření plán skutečného provedení.
Který z nich je snazší číst?
V závislosti na tom, co vám vyhovuje, můžete najít příklad INNER JOIN snáze čitelný než související dotaz. Osobně v tomto příkladu se mi líbí korelovaný poddotaz, protože se zdá být přímější. Je pro mě snazší vidět, co se počítá.
V mé mysli je INNER JOIN méně přímý. Nejprve musíte vidět, že všechny řádky s podrobnostmi o prodeji jsou vráceny ručně a poté shrnuty. Skutečně to nezískáte, dokud si nepřečtete celé prohlášení.
Který z nich je lepší?
Dejte mi vědět, co si myslíte. Chtěl bych slyšet, zda byste raději použili korelovaný poddotaz nebo příklad INNER JOIN.